Time for another annual roundup from the world of IP addresses. Let’s see what has changed in the past 12 months in addressing the Internet and look at how IP address allocation information can inform us of the changing nature of the network itself.
Back around 1992 the IETF gazed into their crystal ball and tried to understand how the Internet was going to evolve and what demands that would place on the addressing system as part of the “IP Next Generation” study. The staggeringly large numbers of connected devices that we see today were certainly within the range predicted by that exercise. Doubtless, these device numbers will continue to grow. We continue to increase silicon chip production volumes and at the same time continue to refine the production process. But, at that time, we also predicted that the only way we could make the Internet work across such a massive pool of connected devices was to deploy a new IP protocol that came with a massively larger address space. It was from that reasoning that IPv6 was designed, as this world of abundant silicon chips was the issue that IPv6 was primarily intended to solve. The copious volumes of address space were intended to allow us to uniquely assign a public IPv6 address to every such device, no matter how small, or in whatever volume they might be deployed.
But while the Internet has grown at such amazing speed, the deployment of IPv6 continues at a more measured pace. There is still no common sense of urgency about the deployment of this protocol, and still there is no common agreement that the continued reliance on IPv4 is failing us. Much of the reason for this apparent contradiction between the designed population of the IPv4 Internet and the actual device count, which is of course many times larger, is that the Internet rapidly changed from a peer-to-peer architecture to a client/server paradigm. Clients can initiate network transactions with servers but are incapable of initiating transactions with other clients. Network Address Translators (NATs) are a natural fit to this client/server model, where pools of clients share a smaller pool of public addresses, and only require the use of an address while they have an active session with a remote server. NATs are the reason why in excess of 20 billion connected devices can be squeezed into some 2 billion active IPv4 addresses. Applications that cannot work behind NATs are no longer useful and no longer used.
However, the pressures of this inexorable growth in the number of deployed devices in the Internet means that the even NATs cannot absorb these growth pressures forever. NATs can extend the effective addressable space by up to 32 ‘extra’ bits, and they enable the time-based sharing of addresses. Both of these measures are effective in stretching the IPv4 address space to encompass a larger client device pool, but they do not transform the address space into an infinitely elastic resource. The inevitable outcome of this process is that we may see the fragmenting of the IPv4 Internet into a number of disconnected parts, probably based on the service ‘cones’ of the various points of presence of the content distribution servers, so that the entire concept of a globally unique and coherent address pool layered over a single coherent packet transmission realm will be foregone. Alternatively, we may see these growth pressures motivate the further deployment of IPv6, and the emergence of IPv6-only elements of the Internet as the network itself tries to maintain a cohesive and connected whole. There are commercial pressures pulling the network in both of these directions, so it’s entirely unclear what path the Internet will follow in the coming years, but my (admittedly cynical and perhaps jaded) personal opinion lies in a future of highly fragmented network.
Can address allocation data help us to shed some light on what is happening in the larger Internet? Let’s look at what happened in 2022.
IPv4 in 2022
It appears that the process of exhausting the remaining pools of unallocated IPv4 addresses is proving to be as protracted as the process of the transition to IPv6, although by the end of 2021 the end of the old registry allocation model was in sight with the depletion of the residual pools of unallocated addresses in each of the Regional Internet Registries (RIRs).
It is increasingly difficult to talk about “allocations” in today’s Internet. There are still a set of transactions where addresses are drawn from the residual pools of RIR-managed available address space and allocated or assigned to network operators, but at the same time there are also a set of transactions where addresses are traded between network in what is essentially a sale. These address transfers necessarily entail a change of registration details, so the registry records the outcome of a transfer, or sale, in a manner that is similar to an allocation or assignment.
If we want to look at the larger picture of the amount of IPv4 address space that is used or usable by Internet network operators, then perhaps the best metric to use is the total span of allocated and assigned addresses, and the consequent indication of annual change in the change in this total address span from year to year.
What is the difference between “allocated” and “assigned”?
When a network operator or sub-registry has received an allocation it can further delegate that IP address space to their customers along with using it for their own internal infrastructure. When a network operator has received an assignment this can only be used for their own internal infrastructure. [https://www.apnic.net/get-ip/faqs/using-address-space/]
I personally find the distinction between these two terms somewhat of an artifice these days, so from here on I’ll use the term “allocation” to describe both allocations and assignments.
The total IPv4 allocated address pool expanded by some 1.5 million addresses in 2022 on top of a base of 3.685 billion addresses that were already allocated at the start of the year. This represents a growth rate of 0.04% for the year for the total allocated IPv4 public address pool. This is less that one twentieth of the growth rate in 2010 (the last full year before the onset of IPv4 address exhaustion) (Table 1).
| 2010 | 2011 | 2012 | 2013 | 2014 | 2015 | 2016 | 2017 | 2018 | 2019 | 2020 | 2021 | 2022 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Address Span (Billions) | 3.227 | 3.395 | 3.483 | 3.537 | 3.593 | 3.624 | 3.643 | 3.657 | 3.657 | 3.682 | 3.684 | 3.685 | 3.687 |
| Annual Change (Millions) | 241.7 | 168.0 | 88.4 | 53.9 | 55.9 | 30.6 | 19.4 | 13.2 | 0.6 | 24.9 | 2.2 | 1.1 | 1.6 |
| Relative Growth | 8.1% | 5.2% | 2.6% | 1.5% | 1.6% | 0.85% | 0.53% | 0.36% | 0.02% | 0.68% | 0.06% | 0.03% | 0.04% |
Table 1 – IPv4 Allocated addresses by year
Where is this supposedly “new” address space coming from? The old model was that unallocated addresses were held in a single pool by the IANA, and blocks of addresses were passed to RIRs who then allocated them to various end entities, either for their own use or for further allocation. But, the IANA exhausted the last of its available address pools some years ago, and these days it holds just 3 /24 address prefixes (https://www.iana.org/assignments/ipv4-recovered-address-space/ipv4-recovered-address-space.xhtml). Because the option of dividing this tiny address pool into 5 equal chunks of 153.6 individual address is not viable, then these addresses are likely to sit in the IANA Recovered Address registry for some time (i.e. until one of more of the RIRs return more prefixes recovered from the old “legacy” allocated addresses to the IANA, who would then be able to divide the pool equally and distribute them to each the 5 RIRs. This is unlikely to occur.) There are also addresses that have been marked by the IANA as reserved (https://www.iana.org/assignments/ipv4-address-space/ipv4-address-space.xhtml), including blocks of addresses reserved for Multicast use, and the top end of the IPv4 address space, curiously marked as reserved for future use. This latter category is a relatively large pool of 268,435,456 addresses (old former “Class E” space) and if ever there was a “future” for IPv4 then it is now. But exactly how to unlock this space and return it to the general use pool is a problem that so far has eluded a generally workable solution, although efforts to do so have surfaced in the community from time to time.
The topic of releasing the Class E space for use in the public Internet as globally routable unicast address space has been raised from time to time over the past 15 years or so. Some Internet drafts were published for the IETF’s consideration that either directly proposed releasing this space for use (draft-wilson-class-e-02, or outlined the impediments in various host and router implementations that were observed to exist in 2008 when these drafts were being developed (draft-fuller-240space-02).
The proposals lapsed, probably due to the larger consideration at the time that the available time and resources to work on these issues were limited and the result of effort spent in freeing off this IPv4 space for general use was only going to obtain a small extension in the anticipated date of depletion of the remaining IPv4 address pools, while the same amount of effort spent on working on advancing IPv6 deployment was assumed to have a far larger beneficial outcome.
From time to time this topic reappears on various mailing lists, but the debates tend to circle around the same set of topics one more time, and then lapse.
As the IANA is no longer a source of “new” addresses, then we need to look at the RIR practices to find these 1.6M addresses that were allocated in 2022. When IP address space is returned to the RIR or reclaimed by the RIR according to the RIR’s policies it is normally placed in a RIR-reserved pool for a period of time and marked as reserved by the RIR. Marking returned or recovered addresses as reserved for a period of time allows various address prefix reputation and related services, including routing records, some time to record the cessation of the previous state of the addresses prefix, prior to any subsequent allocation. Following some period, which has been observed to be between some months and some years, this reserved space is released for re-use. This is the address space we are seeing as expansion of the allocated address pool in 2022.
The record of annual year-on-year change in allocated addresses per RIR over the same twelve-year period is shown in Table 2. There are some years when the per-RIR pool of allocated addresses shrunk is size. This is generally due to inter-RIR movement of addresses, due to administrative changes in some instances and inter-RIR address transfers in others.
TOTAL
| 2010 | 2011 | 2012 | 2013 | 2014 | 2015 | 2016 | 2017 | 2018 | 2019 | 2020 | 2021 | 2022 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| APNIC | 119.5 | 101.0 | 0.6 | 1.2 | 4.6 | 7.4 | 6.7 | 3.2 | 0.4 | 10.5 | 1.7 | 1.5 | 0.8 |
| RIPE NCC | 52.3 | 40.5 | 37.8 | 1.0 | 33.8 | 4.7 | 4.1 | 3.7 | 0.3 | 12.0 | 0.4 | 2.5 | 4.7 |
| ARIN | 27.2 | 53.8 | 24.3 | 19.0 | -14.1 | 2.3 | -4.8 | -2.3 | -0.3 | -10.1 | -0.9 | -1.7 | -3.8 |
| LACNIC | 17.1 | 13.6 | 17.3 | 26.3 | 18.7 | 1.2 | 1.5 | 1.4 | 0.1 | 2.4 | 1.2 | -0.2 | -0.3 |
| AFRINIC | 8.8 | 9.4 | 8.5 | 6.3 | 12.8 | 15.0 | 11.9 | 7.1 | 0.2 | 10.1 | -0.2 | -0.9 | 0.2 |
| 224.9 | 218.3 | 88.5 | 53.8 | 55.8 | 30.6 | 19.4 | 13.1 | 0.7 | 24.9 | 2.2 | 1.2 | 1.6 |
Table 2 – IPv4 Allocated addresses (millions) – Distribution by RIR
Each of the RIRs are running through their final pools of IPv4 addresses. Some of the RIRs have undertaken address reclamation efforts during 2021, particularly in the area of re-designating previously reserved addresses as available for allocation as noted above, notably in APNIC and LACNIC.
At the end of 2022, across the RIR system there are some 4.4 million addresses are in the Available pool, held mainly in APNIC (2.5 million) and AFRINIC (1.9 million). Some 12 million addresses are marked as reserved, with 5.3 million held by ARIN and 4 million addresses held by AFRINIC. It is evident from this table that there has been a major effort at address reclamation from the “quarantine” pools marked as reserved during 2022 by APNIC, As seen in Table 3, there has been some reduction in the reserved pool in APNIC (1.6M), LACNIC (76K) and RIPE NCC (24K) while the reserved pool in ARIN has risen in size by some 70K addresses, and AFRINIC has risen by some 40K addresses through 2022.
| Available | Reserved | |||||||
|---|---|---|---|---|---|---|---|---|
| RIR | 2020 | 2021 | 2022 | 2020 | 2021 | 2022 | ||
| APNIC | 4,003,072 | 3,533,056 | 2,503,424 | 2,483,968 | 1,787,904 | 151,472 | ||
| RIPE NCC | 328,448 | – | – | 965,728 | 762,104 | 737,496 | ||
| ARIN | 4,352 | 4,608 | 8,448 | 5,509,888 | 5,244,160 | 5,311,488 | ||
| LACNIC | – | 7,168 | 1,024 | 266,240 | 224,768 | 148,480 | ||
| AFRINIC | 1,925,888 | 1,652,480 | 1,920,256 | 2,853,888 | 4,065,024 | 4,104,960 | ||
| TOTAL | 6,261,760 | 5,197,312 | 4,433,152 | 12,079,712 | 12,083,960 | 10,453,896 | ||
Table 3 – IPv4 Available and Reserved Pools December 2022
The RIR IPv4 address allocation volumes by year are shown in Figure 1, but it is challenging to understand precisely what is meant by an allocation across the entire RIR system as there are some subtle but important differences between RIRs, particularly as they relate to the handling of transfers of IPv4 addresses.
In the case of ARIN, a transfer between two ARIN-serviced entities is conceptually treated as two distinct transactions: a return of the addresses to the ARIN registry and a new allocation from ARIN. The date of the transfer is recorded as the new allocation date in the records published by the RIR. Other RIRs treat an address transfer in a manner analogous to a change of the nominated holder of the already-allocated addresses, and when processing a transfer, the RIR’s records preserve the original allocation date for the transferred addresses. When we look at the individual transaction records in the published RIR data, and collect then by year, then in the case of ARIN the collected data includes the volume of transferred addresses that were processed in that year, while the other RIRs only include the allocations performed in that year.
In order to provide a view across the entire system its necessary to use an analysis approach that can compensate for these differences in the ways RIRs record address transactions. In this study, an allocation is defined here as a state transition in the registry records from reserved or available to an allocated state. This is intended to separate out the various actions associated with processing address transfers, which generally involve no visible state change, as the transferred address block remains allocated across the transfer, from allocations. This is how the data used to generate Figure 1 has been generated from the RIR published data, comparing the status of the address pools at the end of each year to that of the status at the start of the year. An allocation in that year is identified if the allocated address block was not registered as allocated at the start of the year.
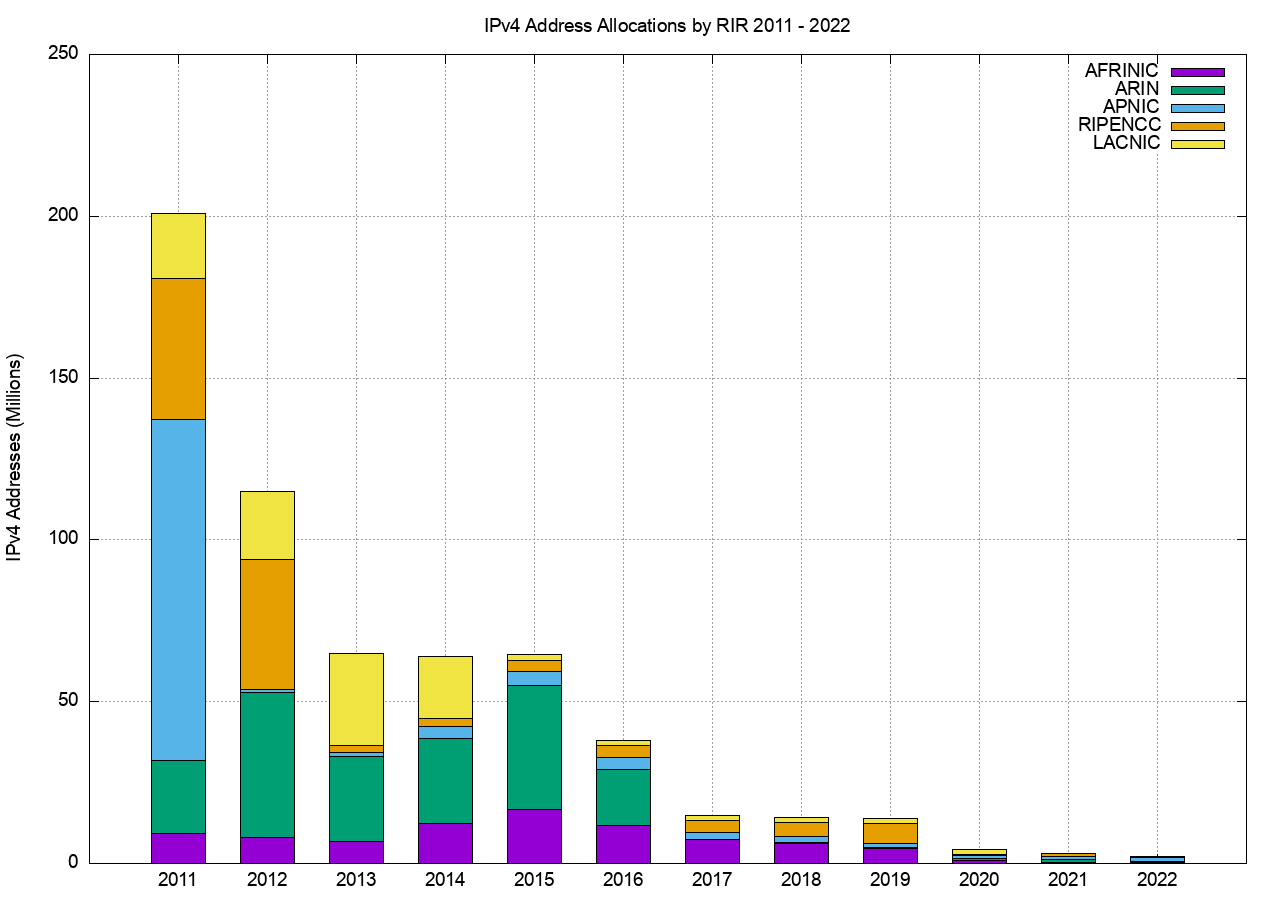
Figure 1 – IPv4 Address Allocations by RIR by year
The number of RIR IPv4 allocations by year, once again generated by using the same data analysis technique as used for Figure 1, are shown in Figure 2.
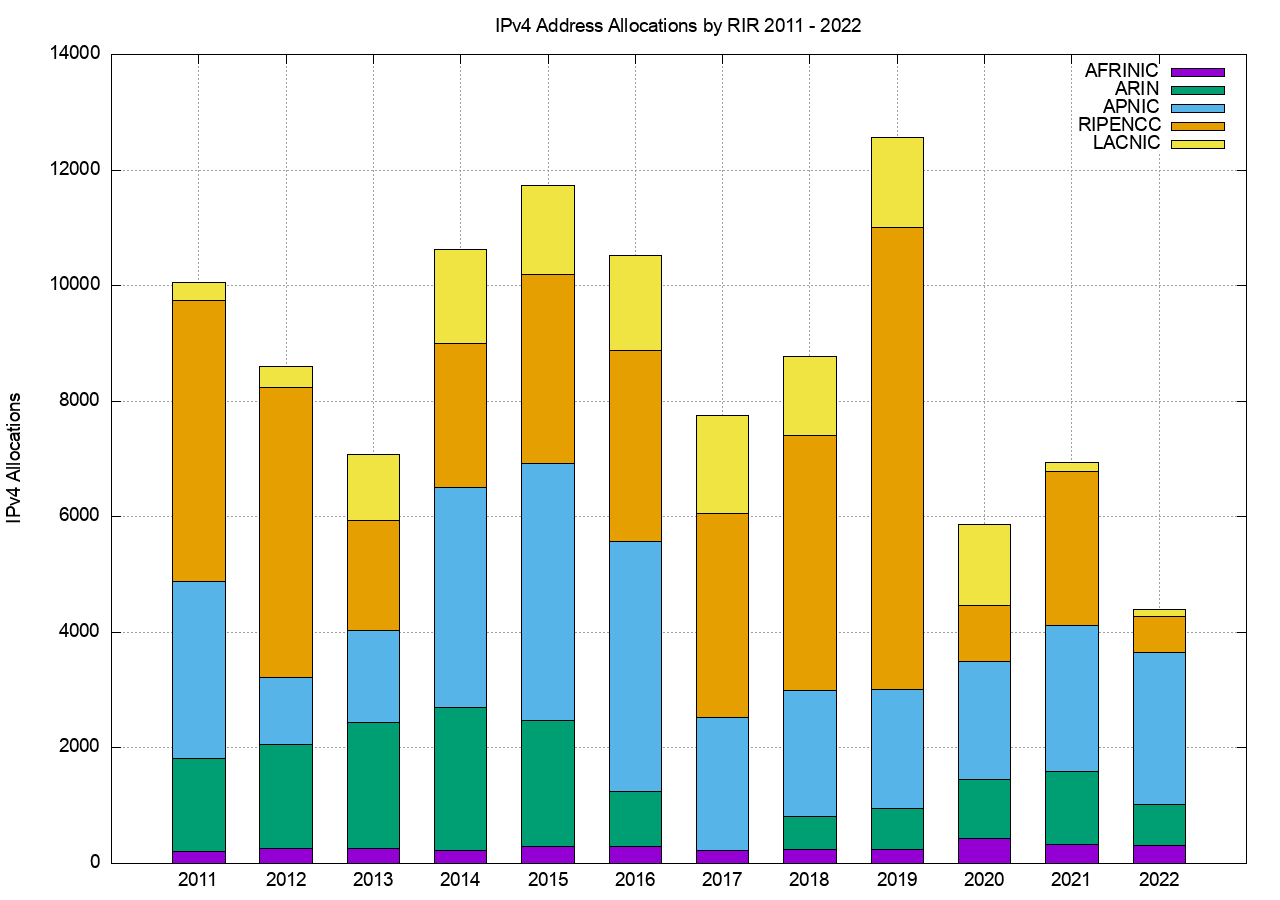
Figure 2 – IPv4 Allocations by RIR by year
It is clear from these two figures that the average size of an IPv4 address allocation has shrunk considerably in recent years, corresponding to the various IPv4 address exhaustion policies in each of the RIRs.
IPv4 Address Transfers
In recent years, the RIRs have permitted the registration of IPv4 transfers between address holders, as a means of allowing secondary re-distribution of addresses as an alternative to returning unused addresses to the registry. This has been in response to the issues raised by IPv4 address exhaustion, where the underlying motivation as to encourage the reuse of otherwise idle or inefficiently used address blocks through the incentives provided by a market for addresses, and to ensure that such address movement is publically recorded in the registry system.
The numbers of registered transfers in the past nine years is shown in Table 4. This includes both inter-RIR and intra-RIR transfers. It also includes both the merger and acquisition-based transfers and the other grounds for of address transfers. Each transfer is treated as a single transaction, and in the case of inter-RIR transfers, this is accounted in the receiving RIR’s totals.
| Recieving RIR | 2012 | 2013 | 2014 | 2015 | 2016 | 2017 | 2018 | 2019 | 2020 | 2021 | 2022 |
|---|---|---|---|---|---|---|---|---|---|---|---|
| APNIC | 159 | 185 | 302 | 451 | 841 | 834 | 487 | 528 | 781 | 786 | 650 |
| RIPE NCC | 10 | 171 | 1,054 | 2,836 | 2,373 | 2,451 | 3,774 | 4,221 | 4,696 | 5,743 | 4,410 |
| ARIN | 3 | 22 | 26 | 26 | 68 | 94 | 150 | 122 | |||
| LACNIC | 2 | 3 | 9 | 15 | |||||||
| AFRINIC | 17 | 27 | 26 | 80 | 54 | ||||||
| Total | 169 | 356 | 1,356 | 3,290 | 3,236 | 3,311 | 4,306 | 4,844 | 5,600 | 6,768 | 5,251 |
Table 4 – IPv4 Address Transfers per year
The differences between RIRs reported numbers are interesting. The policies relating to address transfers do not appear to have been adopted to any significant extent by address holders in AFRINIC and LACNIC serviced regions, while uptake in the RIPE NCC service region appears to be very enthusiastic!
A slightly different view is that of the volume of addresses transferred per year (Table 5).
| Recieving RIR | 2012 | 2013 | 2014 | 2015 | 2016 | 2017 | 2018 | 2019 | 2020 | 2021 | 2022 |
|---|---|---|---|---|---|---|---|---|---|---|---|
| APNIC | 1.7 | 2.5 | 3.9 | 6.6 | 8.2 | 4.9 | 10.0 | 4.3 | 16.6 | 6.5 | 3.2 |
| RIPE NCC | 0.1 | 2.0 | 9.6 | 11.6 | 9.2 | 24.6 | 19.5 | 26.9 | 18.2 | 16.2 | 36.2 |
| ARIN | 0.1 | 0.3 | 0.2 | 0.3 | 0.2 | 0.2 | 3.0 | ||||
| LACNIC | AFRINIC | 0.2 | 0.5 | 1.2 | 3.4 | 0.5 | |||||
| Total | 1.7 | 4.5 | 13.6 | 18.2 | 17.6 | 29.7 | 29.7 | 31.9 | 36.2 | 26.4 | 42.9 |
Table 5 – Volume of Transferred IPv4 Addresses per year (Millions of addresses)
A plot of these numbers is shown in Figures 3 and 4.
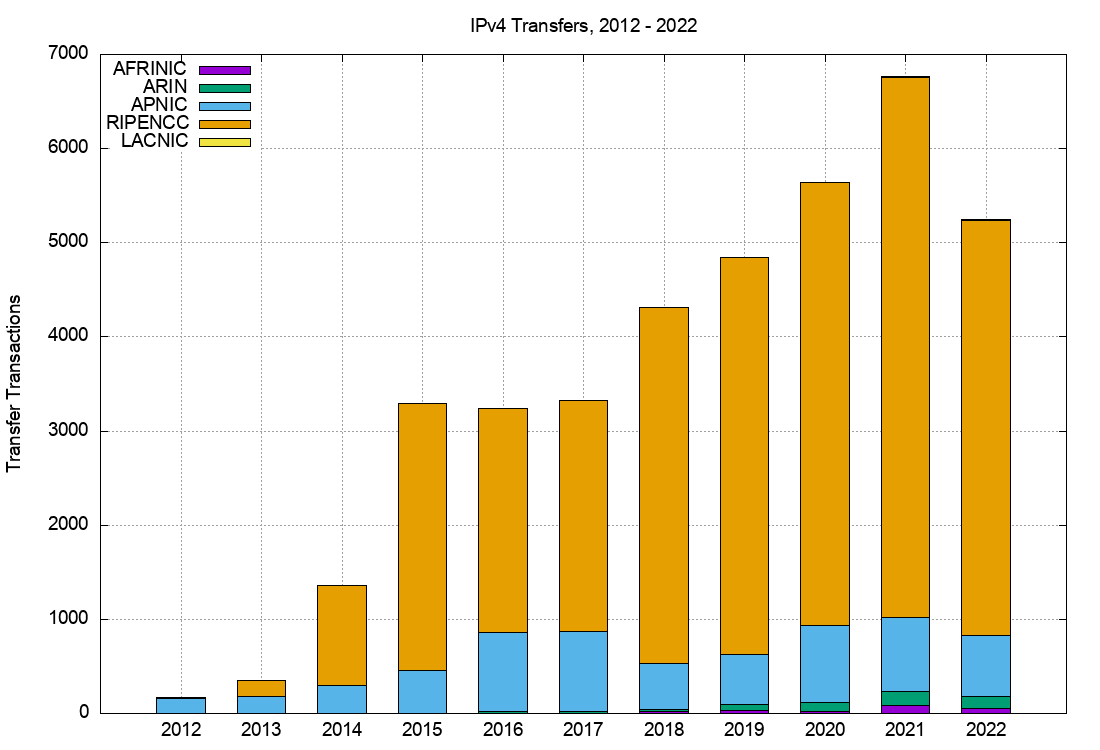
Figure 3 – Number of Transfers: 2012 – 2022
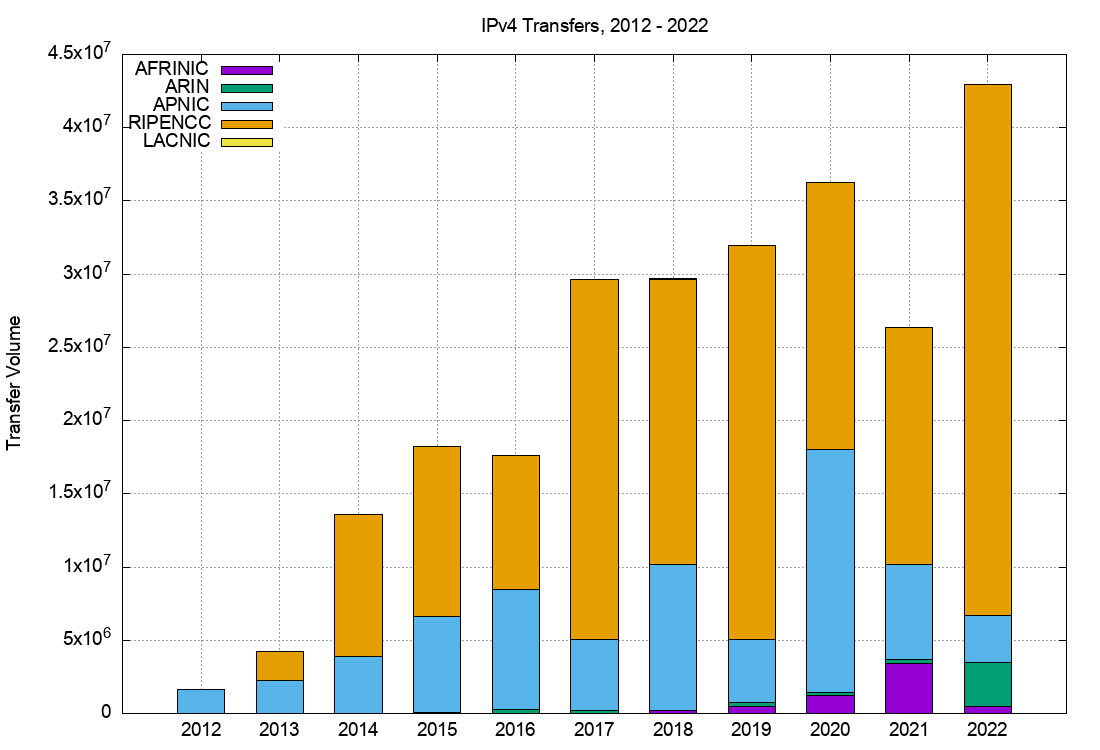
Figure 4 – Volume of Transferred Addresses: 2012 – 2022
The aggregate total of addresses that have been listed in these transfer logs since 2012 is some 252 million addresses, or the equivalent of 12.5 /8s, which is some 7% of the total delegated IPv4 address space of 3.7 billion addresses. However, that figure is likely to be an overestimation as a number of addresses have been transferred multiple times over this period.
Are Transfers Performing Unused Address Recovery?
This data raises some questions about the nature of transfers. The first question is whether address transfers have managed to be effective in dredging the pool of allocated but unadvertised public IPv4 addresses and recycling these addresses back into active use.
It was thought that by being able to monetize these addresses, holders of such addresses may have been motivated to convert their networks to use private addresses and resell their holding of public addresses. In other words, the opening of a market in addresses would provide incentive for otherwise unproductive address assets to be placed on the market. Providers who had a need for addresses would compete with other providers who had a similar need in bidding to purchase these addresses. In conventional market theory the most efficient user of addresses (here “most efficient” is based on the ability to use addresses to generate the greatest revenue) would be able to set the market price. Otherwise unused addresses would be put to productive use, and as long as demand outstrips supply the most efficient use of addresses is promoted by the actions of the market. In theory.
However, the practical experience with transfers is not so clear. The data relating to address re-cycling is inconclusive, in that between 2011 and late 2017 the pool of unadvertised addresses sat between some 38 and 40 /8s. This pool of unadvertised addresses rose from the start of 2018 and by early 2020 there were just under 50 /8s that were unadvertised in the public Internet. This 2-year period of increase in the unadvertised address pool appeared to be a period where IPv4 addresses were being hoarded, though such a conclusion from just this high-level aggregate date is highly speculative and probably unjustified.
There has been a substantial reduction in the size of this unadvertised address pool across 2021. The major change in 2021 was the announcement in the Internet’s routing system of some seven /8s from the address space originally allocated to the US Department of Defence in the early days of the then ARPANET. At the end of 2021 AS749 originates more IPv4 addresses than any other network, namely some 211,581,184 addresses, or the equivalent of a /4.34 in prefix length notation, or some 5% of the total IPv4 address pool.
Across 2022 the previous trend of an increasingly large pool of unadvertised addresses resumed its rise.
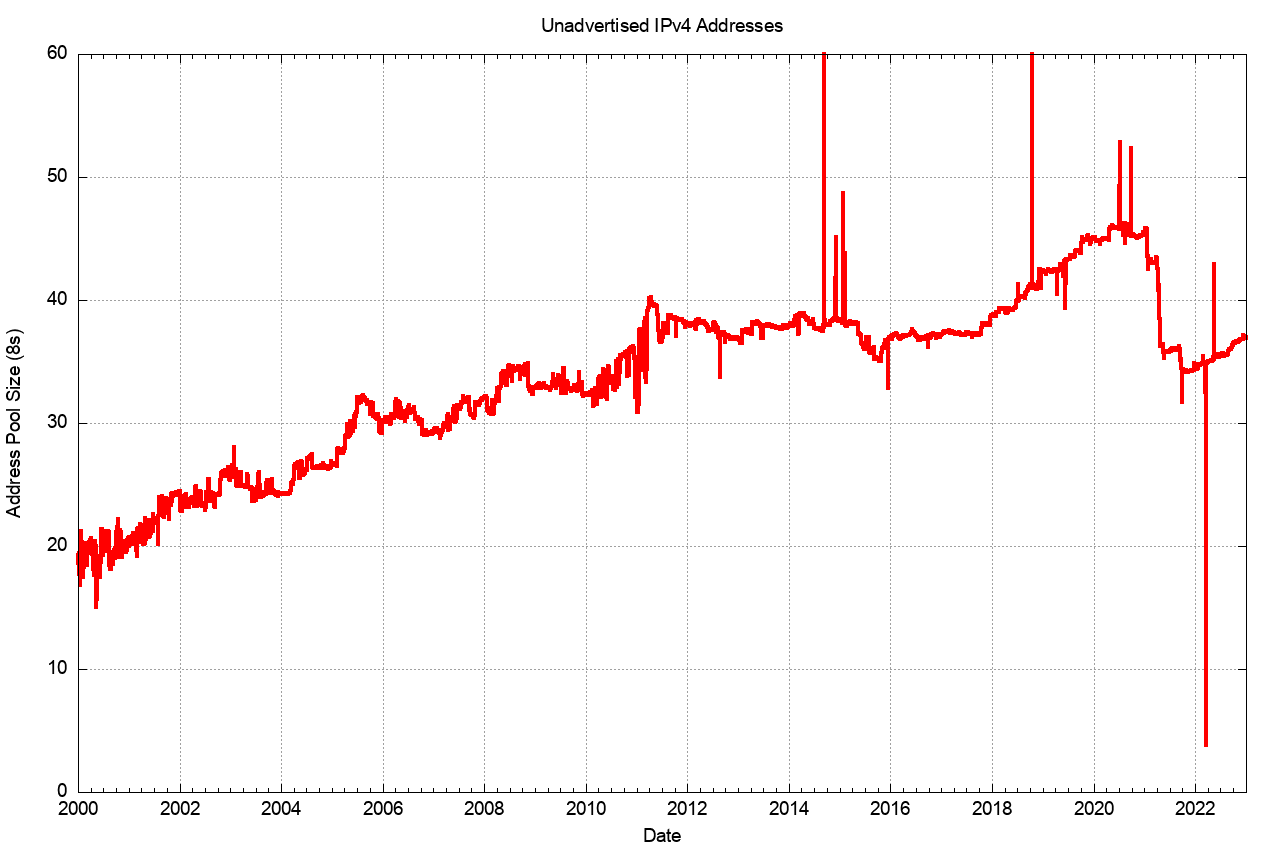
Figure 5 – IPv4 Unadvertised Address Pool Size
The larger picture of the three IPv4 address pool sizes, allocated, advertised and unadvertised since the start of 2000 is shown in Figure 6a. The onset of more restrictive address policies coincides with the exhaustion of the central IANA unallocated address pool in early 2011, and the period since that date has seen the RIRs run down their address pools.
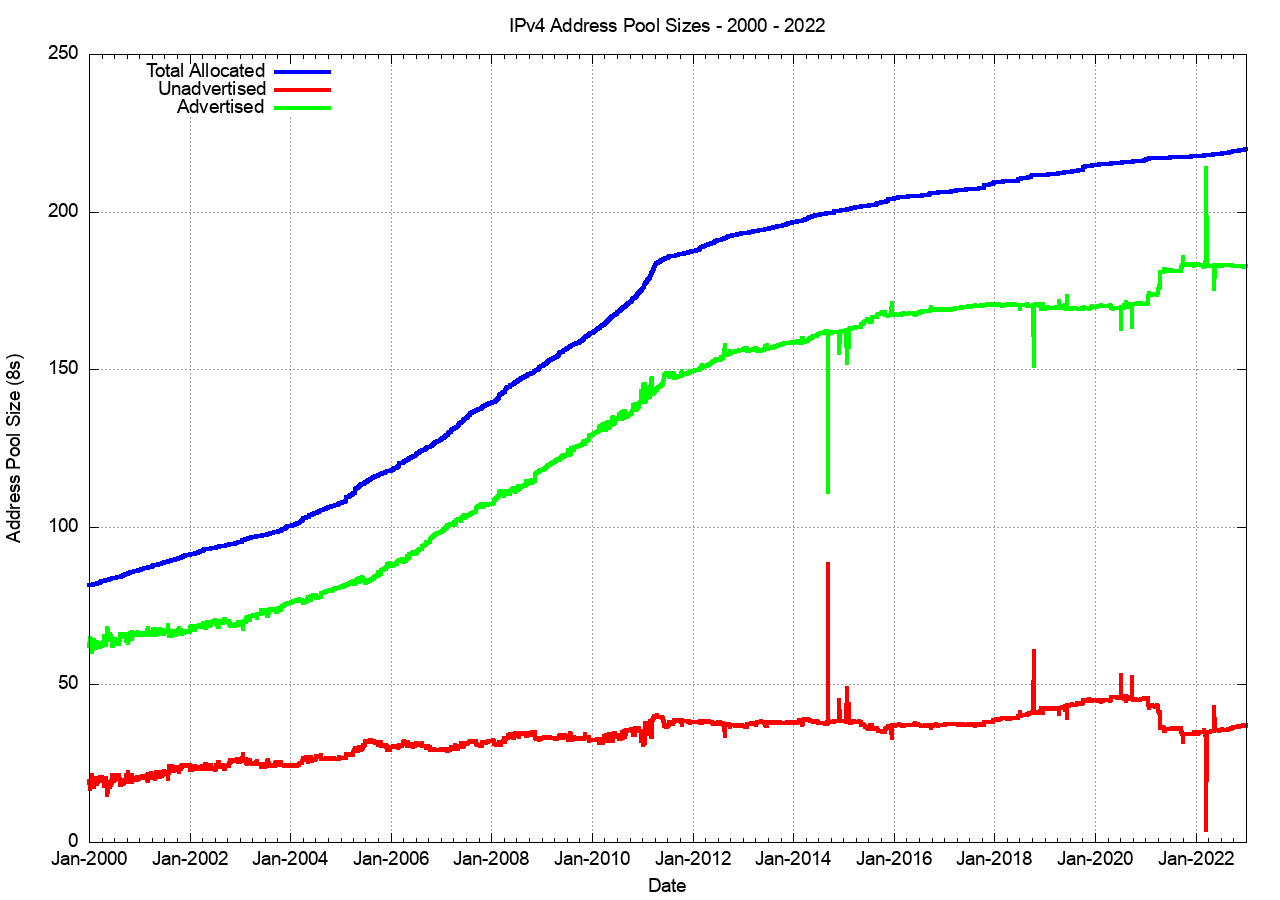
Figure 6a – IPv4 Address Pools 2000 – 2022
We can also look at 2022, looking at the changes in these address pools since the start of the year, as shown in Figure 6b. The total span of advertised addresses has fallen by some 500K addresses through the year. The RIRs also recorded 2M allocated addresses through the year, which has resulted in a growth of the unadvertised address pool of 2.5M addresses for the year.
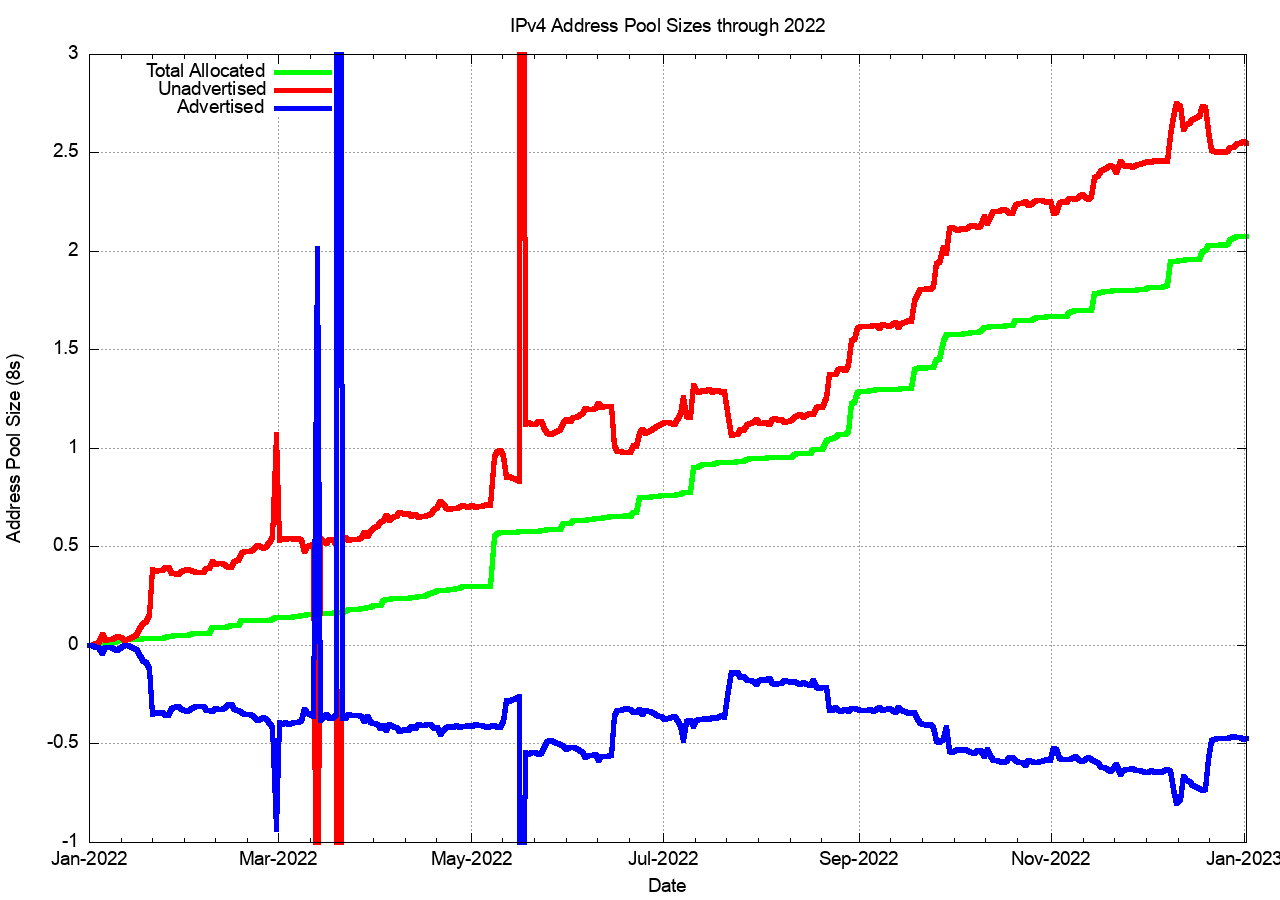
Figure 6b – IPv4 Address Pool Changes through 2021
In relative terms, expressed as a proportion of the total pool of allocated IP addresses, the unadvertised address pool dropped from 28% of the total allocated address pool in 2011 to a low of some 24% at the start of 2016, and subsequently risen to 29% by the end of 2020. During 2021, this figure has dropped to 20%, largely due to the advertisement of the legacy US Department of Defence address space, rather than the activation of previously unadvertised address space. This points to a conclusion that address transfer activity has not made a substantial change in the overall picture of address utilisation efficiency in the past 12 months (Figure 7).
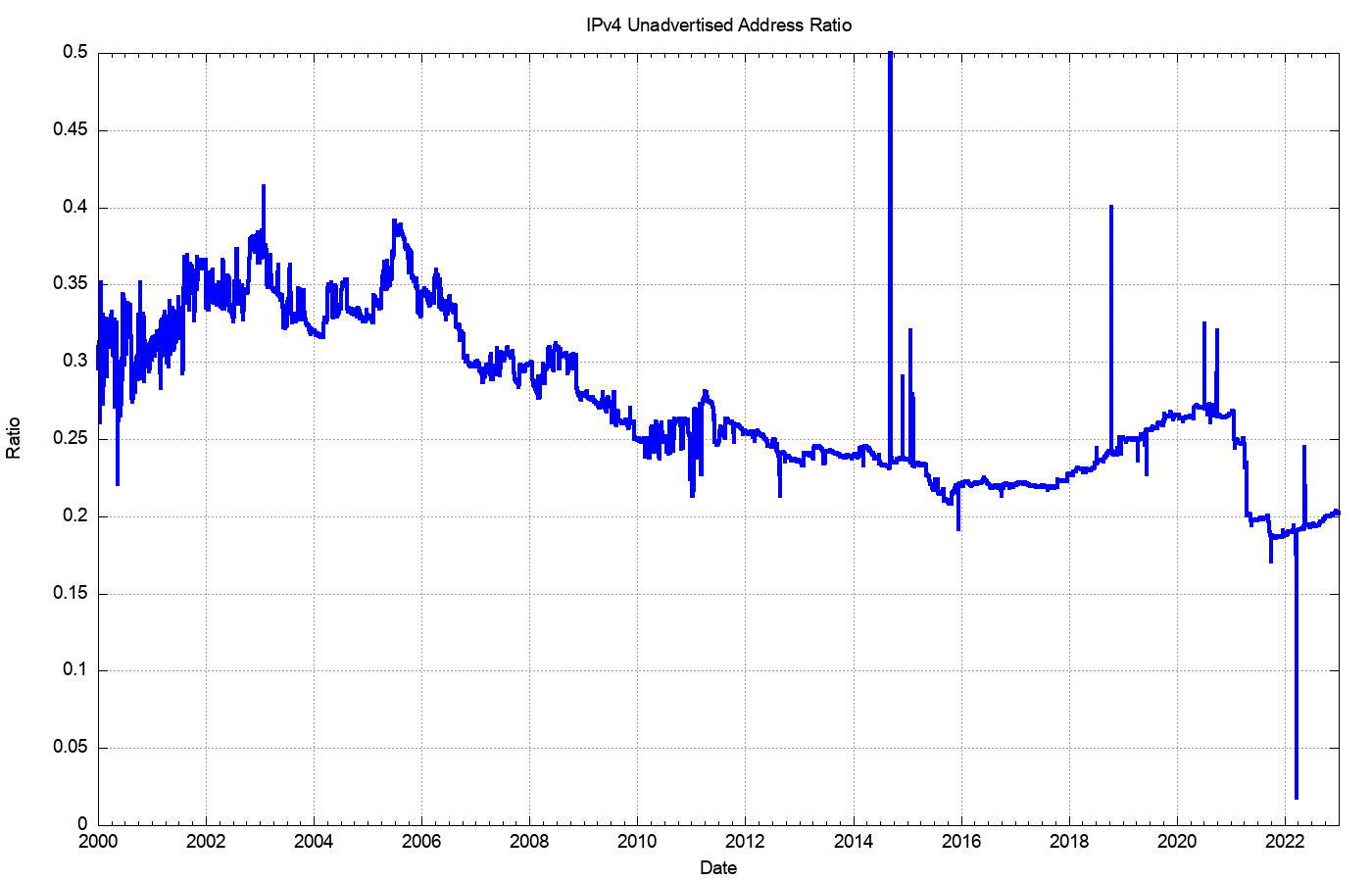
Figure 7 – Ratio of Unadvertised Pool Size to Total Pool Size
This data also shows a somewhat sluggish transfer market. The number of transfer transactions is rising, but the total volume of transferred addresses is falling. The address market has not been ineffective in flushing out otherwise idle addresses and re-deploying them into the routed network.
However, as with all other commodity markets, the market price of the commodity reflects the balancing of supply and demand and the future expectations of supply and demand. What can be seen in the price of traded IPv4 addresses over the past 8 years? One of the address brokers, Hilco Streambank, publish the historical price information of transactions (if only all the address brokers did the same, as a market with open price information for transactions can operate more efficiently and fairly than markets where price information is occluded). Figure 8 uses the Hilco Streambank transaction data to produce a time series of address price.
There are a number of distinct behaviour modes in this data. The initial data prior to 2016 reflected a relatively low volume of transactions with stable pricing just below $10 per address. Over the ensuing 4 years, up to the start of 2019 the price doubled, with small blocks (/24s and /23as) attracting a price premium. The price stabilised for the next 18 months at between $20 to $25 per address, with large and small blocks trading as a similar unit price. The 18 months up to the start of 2022 saw a new dynamic which was reflective of an exponential rise in prices, and the price lifted to between $45 and $60 per address by the end of 2021. The year 2022 saw the average market price drop across the year, but the variance in prices increased and trades at the end of the year were recorded at prices of between $40 to $60 per address. For an undistinguished commodity market where one address value is indistinguishable for any other this 50% price variation is unanticipated and somewhat unusual.
If prices are reflective of supply and demand it appears that demand has increased at a far greater level than supply, and the price across 2022 reflects some form of scarcity premium being applied to addresses in recent times (Figure 8).
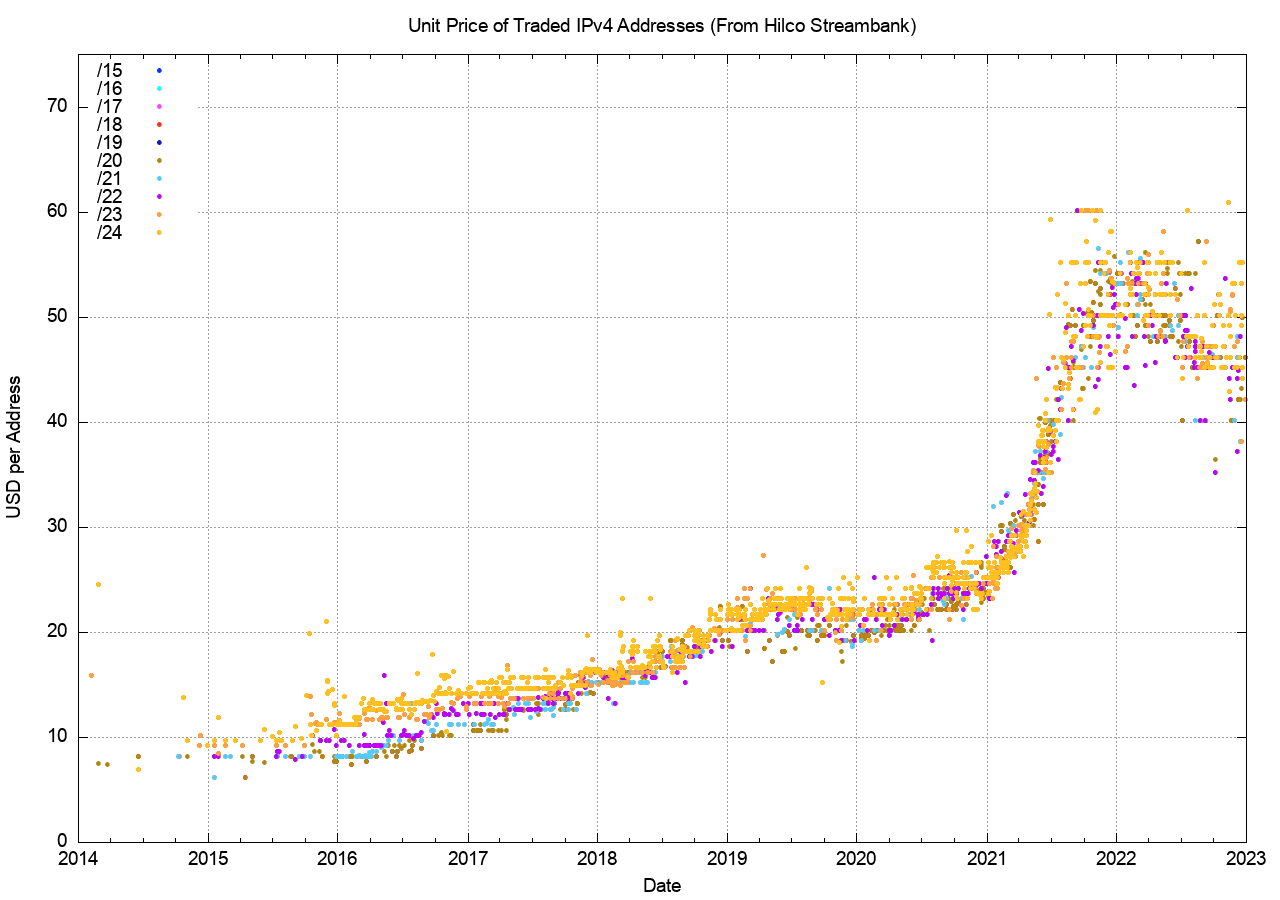
Figure 8 – IPv4 Price Time Series (data from Hilco Streambank)
Is supply of tradable IPv4 address declining? One way to provide some insight into answering this question is to look at the registration age of transferred addresses. Are such addresses predominately recently allocated addresses, or are they longer held address addresses where the holder is wanting to realise the inherent value in otherwise unused assets? The basic question concerns the age distribution of transferred addresses where the age of an address reflects the period since it was first allocated or assigned by the RIR system.
The cumulative age distribution of transferred addresses by transaction is shown on a year-by-year basis in Figures 9 and 10. Some 15% of all transferred addresses in 2022 were drawn from legacy address holders, as shown in Figure 9. It appears that the effort to recycle the legacy address pool has all but run its course and the volume of transferred legacy addresses has declined sharply.
Address holders appear to hold recently allocated addresses for the policy-mandated minimum holding period of some 2 years, but then a visible proportion of these holders transfer these addresses on the market. In previous years some 8% of addresses that were transferred were originally allocated up to 5 years prior to the transfer. In 2022 this number has fallen to 4%, which is presumably related to the smaller volumes of address allocations in 2022 rather than any change in behaviours of address holders.
Figure 10 shows the cumulative age distribution of transfer transactions, and the disparity between the two distributions for 2022 show that recent individual allocations have been far smaller in size but are still being traded. Some 20% of the recorded transfer transactions in 2022 refer to an address prefix that was allocated within the past 5 years, yet these transactions encompass less than 2% of the inventory of transferred addresses in 2022. Some 30% of the volume of transferred addresses were originally allocated 20 or more years ago, while these transactions are recorded in just 12% of the transfers recorded in 2022.
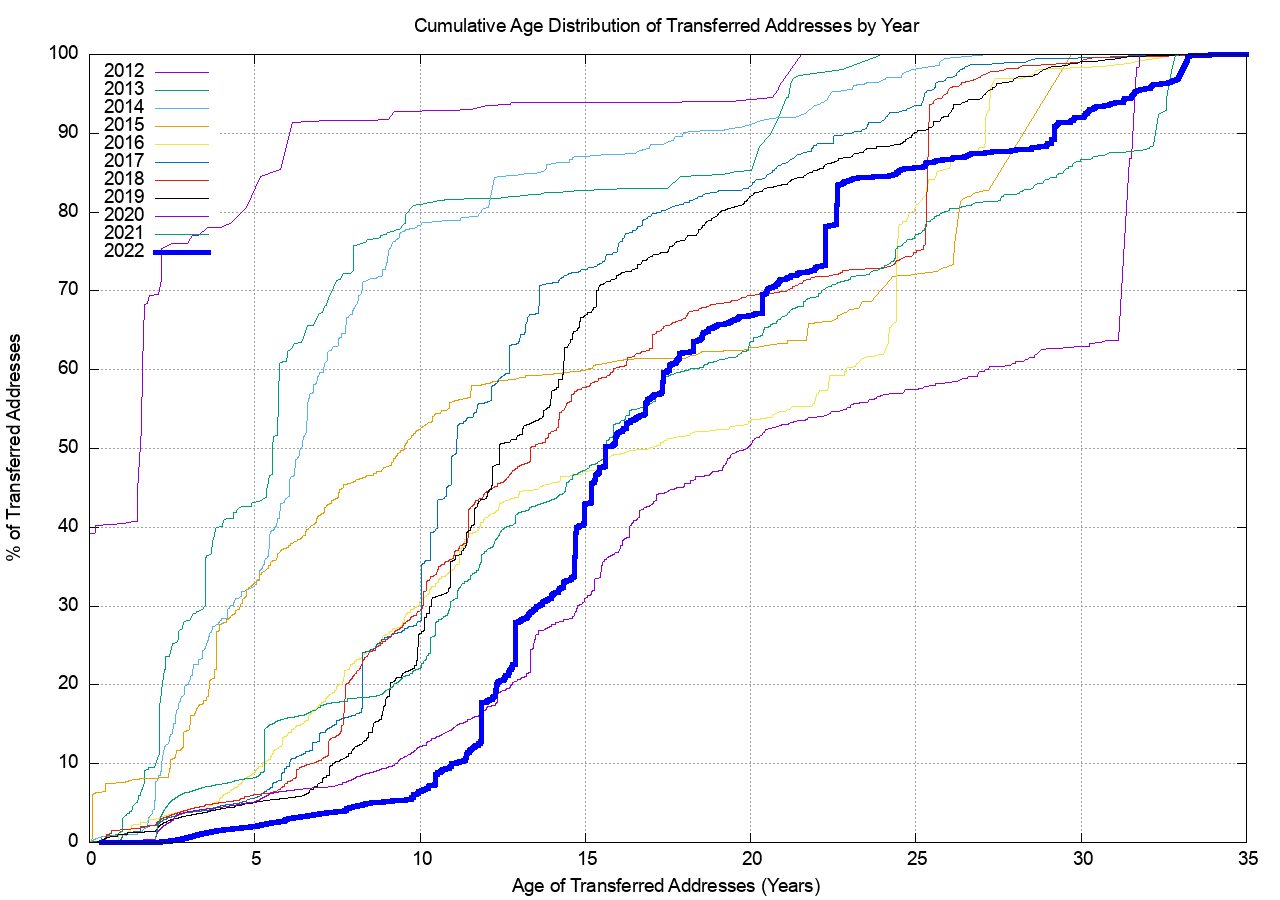
Figure 9 – Age distribution of transferred addresses
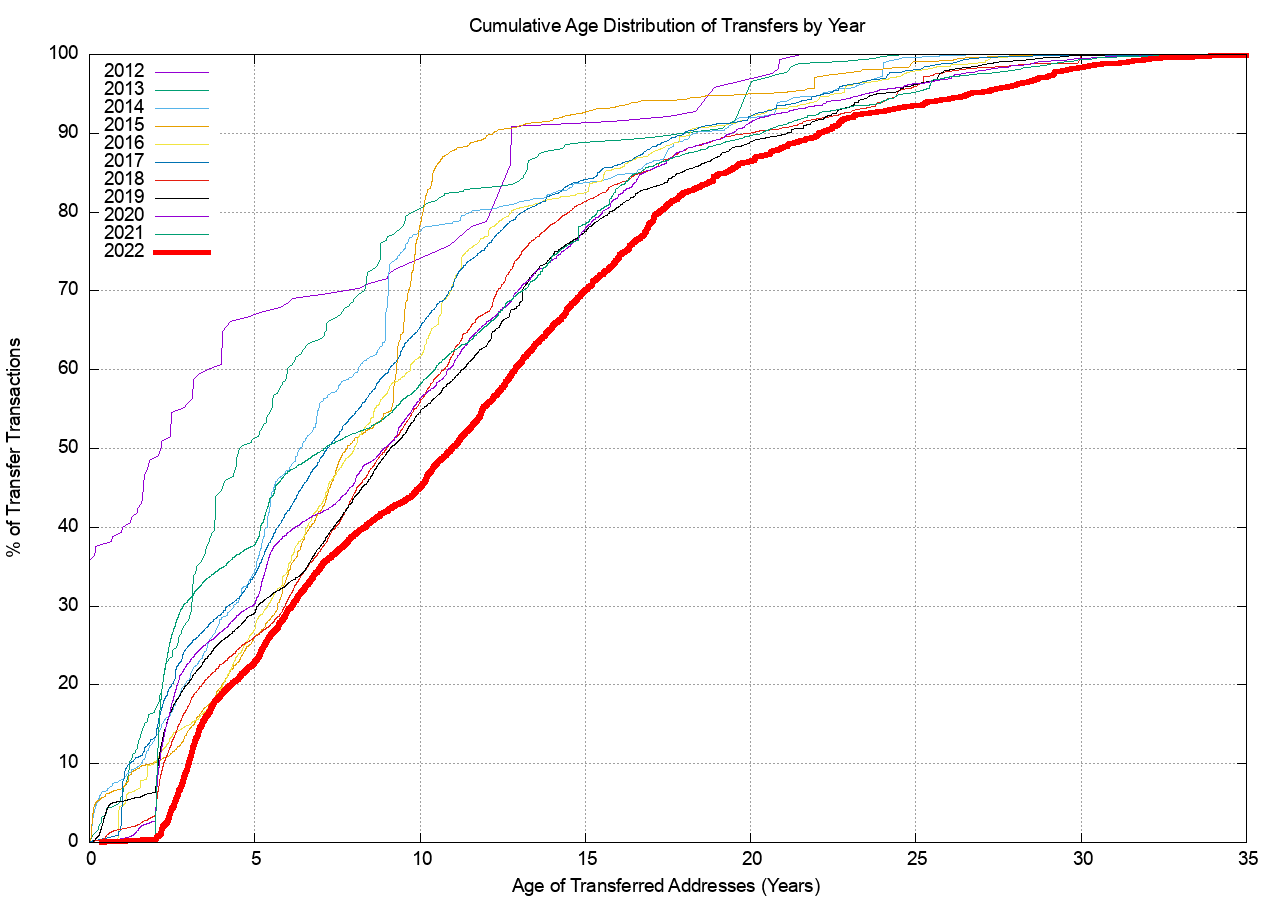
Figure 10 – Age distribution of transfer transactions
There are a number of motivations driving the transfer process in 2022. One is the factor that demand is outstripping supply and price escalation is an inevitable consequence. This may motivate some network operators to purchase addresses early, in the expectation that further delay will encounter higher prices. This factor also may motivate some address holder to defer the decision to sell their addresses, in that delay will improve the price. Taken together, these motivations can impair market liquidity and create a feedback loop that causes price escalation. This appears to be the case in 2021. The second factor is IPv6 deployment. Many applications prefer to use IPv6 over IPv4 if they can (the so-called “Happy Eyeballs” protocol for protocol selection). For a dual stack access network this means that the more the services that they use are provisioned with dual stack the lower the traffic volume that uses IPv4, and the lower the consumption pressure on their IPv4 CG-NATs, which reduces their ongoing demand for IPv4 address space. This reduced demand for additional IPv4 addresses has an impact on the market price. A falling market price acts as a motivation for sellers to bring their unused address inventory to market sooner, as further delay will only result in a lower price.
The overriding feature of this address market is the level of uncertainty within the market over the state of the IPv6 transition, coupled with the uncertainty over the further growth of the network. This high degree of uncertainty may lie behind the very high variance of individual transfer transaction prices in 2022, as shown in Figure 8.
Are address transfers effectively recovering and recycling address blocks that have fallen into disuse, and passing them back into active use? The available data indicates that this is not the dominant factor in current address transfers. The more prevalent current behaviour is where transfers obtain allocations from the RIPE NCC registry, hold it for the policy-mandated minimum holding time, and then monetise the addresses by trading them on the transfer market. This was the concern of many in the community when address transfer markets were first considered, namely that IP addresses become the subject of speculative markets and have little to do with servicing deployed Internet networks.
Do Transfers Fragment the Address Space?
The next question is whether the transfer process is further fragmenting the address space by splitting up larger address blocks into successively smaller address blocks. There are 38,696 transactions described in the RIRs’ transfer registries from the start of 2012 until the start of 2023, and of these 9,963 entries list transferred address blocks that are smaller than the original allocated block. Some 26% of transfers implicitly perform fragmentation of the original allocation.
These 9,963 transfer entries that have fragmented the original allocation are drawn from 5,047 such original allocations. On average the original allocation is split into 2 smaller address blocks. This data implies that the answer to this question is that address blocks are being fragmented as a result of address transfers, but in absolute terms this is not a major issue. There are some 236,502 distinct address allocations from the RIRs to end entities as of the end of 2021, and the fragmentation reflected in 9,963 more specific entries of original address blocks is around 4.2% of the total pool of allocated address prefixes.
Imports and Exports of Addresses
The next question concerns the international flow of transferred addresses. Let’s look at the ten economies that sourced the greatest volume of transferred addresses, irrespective of their destination (i.e. including ‘domestic’ transfers within the same economy) (Table 6), and the ten largest recipients of transfers (Table 7), and the ten largest international address transfers (Table 8). We will use the RIR-published transfer data for 2021 as basis for these tables.
| Rank | CC | Addresses | Source Economy |
|---|---|---|---|
| 1 | FR | 16,569,600 | France |
| 2 | US | 7,325,440 | USA |
| 3 | DE | 3,719,488 | Germany |
| 4 | RU | 1,795,328 | Russia |
| 5 | GB | 1,781,504 | United Kingdom |
| 6 | CN | 1,291,520 | China |
| 7 | BE | 1,123,584 | Belgium |
| 8 | CH | 1,052,672 | Switzerland |
| 9 | ID | 862,464 | Indonesia |
| 10 | IT | 643,456 | Italy |
Table 6 – Top 10 Countries Sourcing Transferred IPv4 addresses in 2022
| Rank | CC | Addresses | Destination Economy |
| 1 | FR | 16,553,472 | France |
| 2 | GB | 4,987,392 | United Kingdom |
| 3 | US | 3,600,384 | USA |
| 4 | DE | 3,447,360 | Germany |
| 5 | SE | 2,431,232 | Sweden |
| 6 | RU | 1,797,376 | Russia |
| 7 | SG | 1,209,600 | Singapore |
| 8 | BE | 1,057,024 | Belgium |
| 9 | JP | 582,656 | Japan |
| 10 | NL | 542,976 | Netherlands |
Table 7 – Top 10 Countries Receiving Transferred IPv4 addresses in 2020
There are many caveats about this data collection, particularly relating to the precise meaning of this economy-based geolocation. Even if we use only the country-code entry in the RIR’s registry records, then we get a variety of meanings. Some RIRs use the principle that the recorded country code entry corresponds to the physical location of the headquarters of nominated entity that is the holder of the addresses, irrespective of the locale where the addresses are used on the Internet. Other RIRs allow the holder to update this geolocation entry to match the holder’s intended locale where the addresses will be used. It is generally not possible to confirm the holder’s assertion of location, so whether these self-managed records reflect the actual location of the addresses or reflect a location of convenience is not always possible to determine. When we look at the various geolocation services, of which Maxmind is a commonly used service, where are similar challenges of location. These services generally intend to associate an address with a location that relates to where the address is physically located. At times this is not easy to establish, such as with tunnels used in VPNs. Is the “correct” location the location of the tunnel ingress or tunnel egress? Many of the fine-grained differences in geolocation services reflect the challenges in dealing with VPNs and the various ways these location services have responded. There is also the issue of cloud-based services. Where the cloud service uses anycast the address is located in many locations at once. In the case where the cloud uses conventional unicast, the addresses use may be fluid across the cloud service’s points of presence based on distributing addresses to meet the demands for the service. The bottom line is that these location listings are a “fuzzy” approximation rather than a precise indication of location.
With that in mind let’s now look at imports and exports of addresses of 2022 transfers where the source and destination of the transfers are in different economies.
| Rank | From | To | Addresses | Source | Destination |
|---|---|---|---|---|---|
| 1 | US | GB | 3,816,192 | USA | UK |
| 2 | US | SE | 2,123,776 | USA | Sweden |
| 3 | CN | SG | 1,114,112 | China | Singapore |
| 4 | ID | US | 655,616 | Indonesia | USA |
| 5 | CH | US | 641,024 | Switzerland | USA |
| 6 | GB | US | 580,864 | UK | USA |
| 7 | US | CN | 525,312 | USA | China |
| 8 | DE | US | 465,408 | Germany | USA |
| 9 | CH | JP | 262,144 | Switzerland | Japan |
| 10 | IT | US | 147,456 | Italy | USA |
| 11 | NL | DE | 139,776 | Netherlands | Germany |
| 12 | CL | BR | 131,072 | Chile | Brazil |
| 13 | IN | PH | 131,072 | India | Philippines |
| 14 | DE | TR | 111,616 | Germany | Turkey |
| 15 | GB | SE | 101,376 | UK | Sweden |
| 16 | US | DE | 73,216 | USA | Germany |
| 17 | US | JP | 70,144 | USA | Japan |
| 18 | AU | GB | 67,584 | Australia | UK |
| 19 | SE | US | 67,584 | Sweden | USA |
| 20 | JP | US | 67,584 | Japan | USA |
Table 8 – Top 20 Economy-to-Economy IPv4 address transfers in 2020
The 2022 transfer logs contain 3,722 domestic address transfers, with a total of 29,097,664 addresses, with the largest activity by address volume in domestic transfers in France, Germany and Russia. Some 1,612 transfers appear to result in a movement of addresses between countries, involving a total of 14,011,136 addresses.
The outstanding question about this transfer data is whether all address transfers that have occurred have been duly recorded in the registry system. This question is raised because registered transfers require conformance to various registry policies, and it may be the case that only a subset of transfers are being recorded in the registry as a result. This can be somewhat challenging to detect, particularly if such a transfer is expressed as a lease or other form of temporary arrangement, and if the parties agree to keep the details of the transfer confidential.
It might be possible to place an upper bound on the volume of address movements that have occurred in any period is to look at the Internet’s routing system. One way to shed some further light on what this upper bound on transfers might be is through a simple examination of the routing system, looking at addresses that were announced in 2022 by comparing the routing stable state at the start of the year with the table state at the end of the year (Table 9).
| Jan-22 | Jan-23 | Delta | Unchanged | Re-Home | Removed | Added | ||
|---|---|---|---|---|---|---|---|---|
| Announcements | 906,456 | 941,707 | 35,251 | 728,538 | 23,100 | 77,409 | 112,660 | |
| Address Span (/8s) | 249.61 | 249.61 | (0.00) | 226.58 | 2.74 | 10.32 | 9.96 | |
| Root Prefixes: | 423,948 | 444,678 | 20,730 | 355,647 | 15,077 | 28,040 | 45,914 | |
| Address Span (/8s) | 183.29 | 182.81 | -0.48 | 169.81 | 1.96 | 5.93 | 5.11 | |
| More Specifics: | 482,508 | 497,029 | 14,521 | 372,891 | 8,023 | 49,369 | 66,746 | |
| Address Span (/8s) | 50.62 | 50.69 | 0.07 | 40.67 | 0.78 | 4.39 | 4.85 |
Table 9 – IPv4 BGP changes over 2022
While the routing table grew by 35,251 entries over the year, the nature of the change is slightly more involved. Some 77,409 prefixes that were announced at the start of the year were removed from the routing system at some time through the year, and 112,660 prefixes were announced by the end of the year that were not announced at the start of the year. More transient prefixes may have appeared and been withdrawn throughout the year of course (see next paragraph), but here we are comparing two snapshots rather than looking at every update message. A further 23,100 prefixes had changed their originating Autonomous System number, indicating some form of change in the prefix’s network location in some manner.
If we look at the complete collection of BGP updates seen from an individual BGP vantage point (AS 131072) across all of 2022 we see a larger collection of transient address prefixes. A total of 1,129,657distinct prefixes were observed through 2022. That implies that some 222,421 additional prefixes seen at some point through the year, from the initial set at the start of the year.
We can compare these prefixes that changed in 2022 against the transfer logs for the two-year period 2021 and 2022. Table 10 shows the comparison of these routing numbers against the set of transfers that were logged in these two years.
| Type | Listed Transfer | Unlisted | Ratio |
|---|---|---|---|
| Re-Homed | |||
| All | 1,294 | 21,806 | 5.6% |
| oot Prefixes | 1,063 | 13,473 | 7.3% |
| Removed | |||
| All | 2,384 | 75,025 | 3.1% |
| Root Prefixes | 1,594 | 26,446 | 5.7% |
| Added | |||
| All | 3,714 | 108,946 | 3.3% |
Table 10 – Routing changes across 2022 compared to the Transfer Log Entries for 2021 – 2022
These figures show that some 3%-7% of changes in advertised addresses from the beginning to the end of the year are reflected as changes as recorded in the RIRs’ transfer logs. This shouldn’t imply that the remaining changes in advertised prefixes reflect unrecorded address transfers. There are many reasons for changes in the advertisement of an address prefix and a change in the administrative controller of the address is only one potential cause. However, it does establish some notional upper ceiling on the number of movements of addresses in 2022, some of which relate to transfer of operational control of an address block, that have not been captured in the transfer logs.
Finally, we can perform an age profile of the addresses that were added, removed and re-homed during 2021 and compare it to the overall age profile of IPv4 addresses in the routing table. This is shown in Figure 11. In terms of addresses that were added in 2022, they differ from the average profile due to a skew in favour of “older” addresses, and 20% of all announced addresses were allocated or assigned more then 30 years ago.
Figure 11 – Change in the size of the BGP routing table across 2022 by Address Prefix Age
However, as IPv4 moves into its final stages we are perhaps now in a position to take stock of the overall distribution of IPv4 addresses and look at where the addresses landed up. Table 11 shows the ten countries that have the largest pools of allocated IPv4 addresses. However, I have to note that the assignation of a country code in an address registration reflects the country where address holder is located (the corporate location), and not necessarily the country where the addresses will be deployed.
| Rank | CC | IPv4 Pool | % Total | Per-Capita | Economy |
|---|---|---|---|---|---|
| 1 | US | 1,617,753,952 | 43.9% | 4.78 | USA |
| 2 | CN | 343,277,568 | 9.3% | 0.24 | China |
| 3 | JP | 190,439,680 | 5.2% | 1.54 | Japan |
| 4 | DE | 123,757,440 | 3.4% | 1.48 | Germany |
| 5 | GB | 119,183,240 | 3.2% | 1.76 | United Kingdom |
| 6 | KR | 112,498,944 | 3.1% | 2.17 | Korea |
| 7 | BR | 87,198,720 | 2.4% | 0.40 | Brazil |
| 8 | FR | 82,354,800 | 2.2% | 1.27 | France |
| 9 | CA | 69,177,344 | 1.9% | 1.80 | Canada |
| 10 | IT | 54,729,024 | 1.5% | 0.93 | Italy |
Table 11 – IPv4 Allocated Address Pools per National Economy
If we divide this address pool by the current population of each national entity, then we can derive an address per capita index. The global total of 3.69 billion allocated addresses with an estimated global population of 8 billion people gives an overall value of 0.53 IPv4 addresses per capita.
| Rank | CC | IPv4 Pool | % Total | Per-Capita | Economy |
|---|---|---|---|---|---|
| 1 | SC | 7,245,056 | 0.2% | 67.64 | Seychelles |
| 2 | VA | 10,752 | 0.0% | 21.08 | Holy See |
| 3 | GI | 253,440 | 0.0% | 7.76 | Gibraltar |
| 4 | US | 1,617,753,952 | 43.9% | 4.78 | United States of America |
| 5 | SG | 25,385,216 | 0.7% | 4.24 | Singapore |
| 6 | MU | 4,777,216 | 0.1% | 3.68 | Mauritius |
| 7 | CH | 26,730,744 | 0.7% | 3.05 | Switzerland |
| 8 | VG | 90,880 | 0.0% | 2.90 | British Virgin Islands |
| 9 | NO | 15,606,032 | 0.4% | 2.87 | Norway |
| 10 | SE | 30,082,280 | 0.8% | 2.85 | Sweden |
| – | XA | 3,686,521,896 | 100.0% | 0.46 | World |
Table 12 – IPv4 Allocated Address Pools ranked per Capita
The full table of IPv4 allocations per national economy can be found at http://resources.potaroo.net/iso3166/v4cc.html.
IPv4 Address Leasing
It is worth noting that the address market includes leasing as well as sales. Should an entity who requires IPv4 addresses enter the market and perform an outright purchase of the addresses from an existing address holder, or should they execute a timed leased to have the use of these addresses for a specified period and presumably return these addresses at the end of the lease? This lease versus buy question is a very conventional question in market economics and there are various well-rehearsed answers to the question. They tend to relate to the factoring of market information and scenario planning.
If a buyer believes that the situation that led to the formation of a market will endure for a long time, and the goods being traded on the market are in finite supply while the level of demand for these goods is increasing, then the market will add an escalating scarcity premium to the price goods being traded. The balancing of demand and supply becomes a function of this scarcity premium imposed on the goods being traded. Goods in short supply tend to become more expensive to buy over time. A holder of these goods will see an increase in the value of the goods that they hold. A lessee will not.
If a buyer believes that the market only has a short lifespan, and that demand for the good will rapidly dissipate at the end of this lifespan, then leasing the good makes sense, in so far as the lessee is not left with a valueless asset when the market collapses.
Scarcity also has several additional consequences, one of which is the pricing of substitute goods. At some point the price of the original good rises to the point that substitution looks economically attractive, even if the substitute good has a higher cost of production or use. In fact, this substitution price effectively sets a price ceiling for the original scarce good.
Some commentators have advanced the view that an escalating price for IPv4 increases the economic incentive for IPv6 adoption, and this may indeed be the case. However, there are other potential substitutes that have been used, most notably NATs (Network Address Translators). While NATs do not eliminate the demand pressure for IPv4, they can go a long way to increase the address utilisation efficiency if IPv4 addresses. NATs allow the same address to be used by multiple customers at different times. The larger the pool of customers that share a common pool of NAT addresses the greater the achievable multiplexing capability.
The estimate as to how long the market in IPv4 addresses will persist is effectively a judgement as to how long IPv4 and NATs can last and how long it will take IPv6 to sufficiently deployed to be viable as an IPv6-only service. At that point in time there is likely to be a tipping point where the pressure for all hosts and networks to support access to services over IPv4 collapses. A that point, the early IPv6-only adopters can dump all their remaining IPv4 resources onto the market as they have no further need for them, which would presumably trigger a level of market panic to emerge as existing holders are faced with the prospect of holding a worthless asset and are therefore under pressure to sell off their IPv4 assets while there are still buyers in the market.
While a significant population of IPv4-only hosts and networks can stall this transition and increase scarcity pressure, if the scarcity pressure becomes too great the impetus of IPv6-only adoption increases to the level that the IPv6-connected base achieves market dominance. When this condition is achieved the IPv4 address market will quickly collapse.
IPv6 in 2020
Obviously, the story of IPv4 address allocations is only half of the story, and to complete the picture it’s necessary to look at how IPv6 has fared over 2022.
IPv6 uses a somewhat different address allocation methodology than IPv4, and it is a matter of choice for a service provider as to how large an IPv6 address prefix is assigned to each customer. The original recommendations published by the IAB and IESG in 2001, documented in RFC3177, envisaged the general use of a /48 prefix as a generally suitable end-site prefix. Subsequent consideration of long term address conservation saw a more flexible approach being taken with the choice of the end site prefix size being left to the service provider. Today’s IPv6 environment has some providers using a /60 end site allocation unit, many using a /56, and many other providers using a /48. This variation makes a comparison of the count of allocated IPv6 addresses somewhat misleading, as an ISP using /48’s for end sites will require 256 times more address space to accommodate a similarly sized same customer base as a provider who uses a /56 end site prefix, and 4,096 times more address space than an ISP using a /60 end site allocation!
For IPv6 let’s use both the number of discrete IPv6 allocations and the total amount of space that was allocated to see how IPv6 fared in 2022.
Comparing 2021 to 2022, the number of individual allocations of IPv6 address space has declined by 25%, whuile the number of IPv4 allocation transactions has delined by 36% (Table 13).
| Allocations | 2011 | 2012 | 2013 | 2014 | 2015 | 2016 | 2017 | 2018 | 2019 | 2020 | 2021 | 2022 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| IPv6 | 3,582 | 3,291 | 3,529 | 4,502 | 4,644 | 5,567 | 5,740 | 6,176 | 6,799 | 5,376 | 5,350 | 4,066 |
| IPv4 | 8,234 | 7,435 | 6,429 | 10,435 | 11,352 | 9,648 | 8,185 | 8,769 | 12,560 | 5,874 | 6,939 | 4,395 |
Table 13 – Number of individual Address Allocations, 2011 – 2022
The amount of IPv6 address space distributed in 2021 is 30% more than the amount that was allocated in 2020 (Table 14).
| Addresses | 2009 | 2010 | 2011 | 2012 | 2013 | 2014 | 2015 | 2016 | 2017 | 2018 | 2019 | 2020 | 2021 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| IPv6 (/32s) | 14,986 | 17,710 | 23,642 | 17,847 | 15,765 | 25,260 | 19,975 | 38,699 | 35,924 | 21,620 | 28,131 | 27,497 | |
| IPv4 (/32s)(M) | 191.7 | 88.8 | 57.7 | 58.8 | 32.3 | 20.8 | 15.1 | 14.1 | 13.9 | 4.2 | 3.1 | 2.1 |
Table 14 – Volume of Address Allocations, 2011 – 2022
Regionally, each of the RIRs saw IPv6 allocation activity in 2022 that was on a par with those seen in the previous year, with the exception of the RIPE NCC where the number of allocations fell by some 50% (Table 15).
| Allocations | 2011 | 2012 | 2013 | 2014 | 2015 | 2016 | 2017 | 2018 | 2019 | 2020 | 2021 | 2022 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| AFRINIC | 129 | 82 | 72 | 59 | 81 | 111 | 110 | 108 | 111 | 108 | 135 | 151 |
| APNIC | 641 | 599 | 540 | 528 | 777 | 1,680 | 1,369 | 1,460 | 1,484 | 1,498 | 1,392 | 1,317 |
| ARIN | 1,035 | 603 | 543 | 489 | 604 | 645 | 684 | 648 | 601 | 644 | 668 | 680 |
| LACNIC | 130 | 251 | 223 | 1,199 | 1,053 | 1,007 | 1,547 | 1,439 | 1,614 | 1,801 | 725 | 635 |
| RIPENCC | 1,647 | 1,756 | 2,151 | 2,227 | 2,129 | 2,124 | 2,030 | 2,521 | 2,989 | 1,325 | 2,430 | 1,283 |
| 3,582 | 3,291 | 3,529 | 4,502 | 4,644 | 5,567 | 5,740 | 6,176 | 6,799 | 5,376 | 5,350 | 4,066 |
Table 15 – IPv6 allocations by RIR
The address assignment data tells a slightly different story. Table 16 shows the number of allocated IPv6 /32’s per year. The total allocation volume was slightly lower than 2021, with a large volume in 2022 .by ARIN. The large allocations in 2022 by Arin include /20s to the US Department of Health and Human Services, the US National Oceanic and Atmospheric Administration, and the US Department of Veterans Affairs. These allocations are of interest as they show signs of protocol migration in sectors that are not directly related to the consumer Internet, and in this case they are US federal government agencies.
| Addresses (/32s) | 2011 | 2012 | 2013 | 2014 | 2015 | 2016 | 2017 | 2018 | 2019 | 2020 | 2021 | 2022 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| AFRINIC | 155 | 4,201 | 66 | 48 | 308 | 76 | 112 | 71 | 360 | 88 | 141 | 387 |
| APNIC | 9,506 | 3,807 | 4,462 | 2,663 | 2,108 | 1,235 | 4,228 | 19,681 | 7,945 | 7,365 | 10,185 | 4,856 |
| ARIN | 2,280 | 1,672 | 12,571 | 5,214 | 642 | 1,087 | 1,372 | 844 | 5,520 | 4,975 | 373 | 13,695 |
| LACNIC | 620 | 4,301 | 158 | 1,314 | 953 | 1,173 | 1,427 | 1,327 | 1,496 | 1,669 | 658 | 563 |
| RIPENCC | 2,425 | 3,729 | 6,385 | 8,608 | 11,754 | 21,689 | 12,836 | 16,776 | 20,603 | 7,523 | 16,774 | 7,996 |
| 14,986 | 17,710 | 23,642 | 17,847 | 15,765 | 25,260 | 19,975 | 38,699 | 35,924 | 21,620 | 28,131 | 27,497 |
Table 16 – IPv6 address allocation volumes by RIR
Dividing addresses by allocations gives the average IPv6 allocation size in each region (Table 16). Overall, the average IPv6 allocation size remains around a /30, with the RIPE NCC and APNIC averaging larger individual IPv6 allocations than the other RIRs.
| Addresses (/32s) | 2011 | 2012 | 2013 | 2014 | 2015 | 2016 | 2017 | 2018 | 2019 | 2020 | 2021 | 2022 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| AFRINIC | /31.7 | /26.3 | /32.1 | /32.3 | /30.1 | /32.5 | /32.0 | /32.6 | /30.3 | /32.3 | /31.9 | /30.6 |
| APNIC | /28.1 | /29.3 | /29.0 | /29.7 | /30.6 | /32.4 | /30.4 | /28.2 | /29.6 | /29.7 | /29.1 | /30.1 |
| ARIN | /30.9 | /30.5 | /27.5 | /28.6 | /31.9 | /31.2 | /31.0 | /31.6 | /28.8 | /29.1 | /32.8 | /27.7 |
| LACNIC | /29.7 | /27.9 | /32.5 | /31.9 | /32.1 | /31.8 | /32.1 | /32.1 | /32.1 | /32.1 | /32.1 | /32.2 |
| RIPENCC | /31.4 | /30.9 | /30.4 | /30.0 | /29.5 | /28.6 | /29.3 | /29.3 | /29.2 | /29.5 | /29.2 | /29.4 |
| /29.9 | /29.6 | /29.3 | /30.0 | /30.2 | /29.8 | /30.2 | /29.4 | /29.6 | /30.0 | /29.6 | /29.2 |
Table 17 – Average IPv6 address allocation size by RIR
The number and volume of IPv6 allocations per RIR per year is shown in Figures 12 and 13.
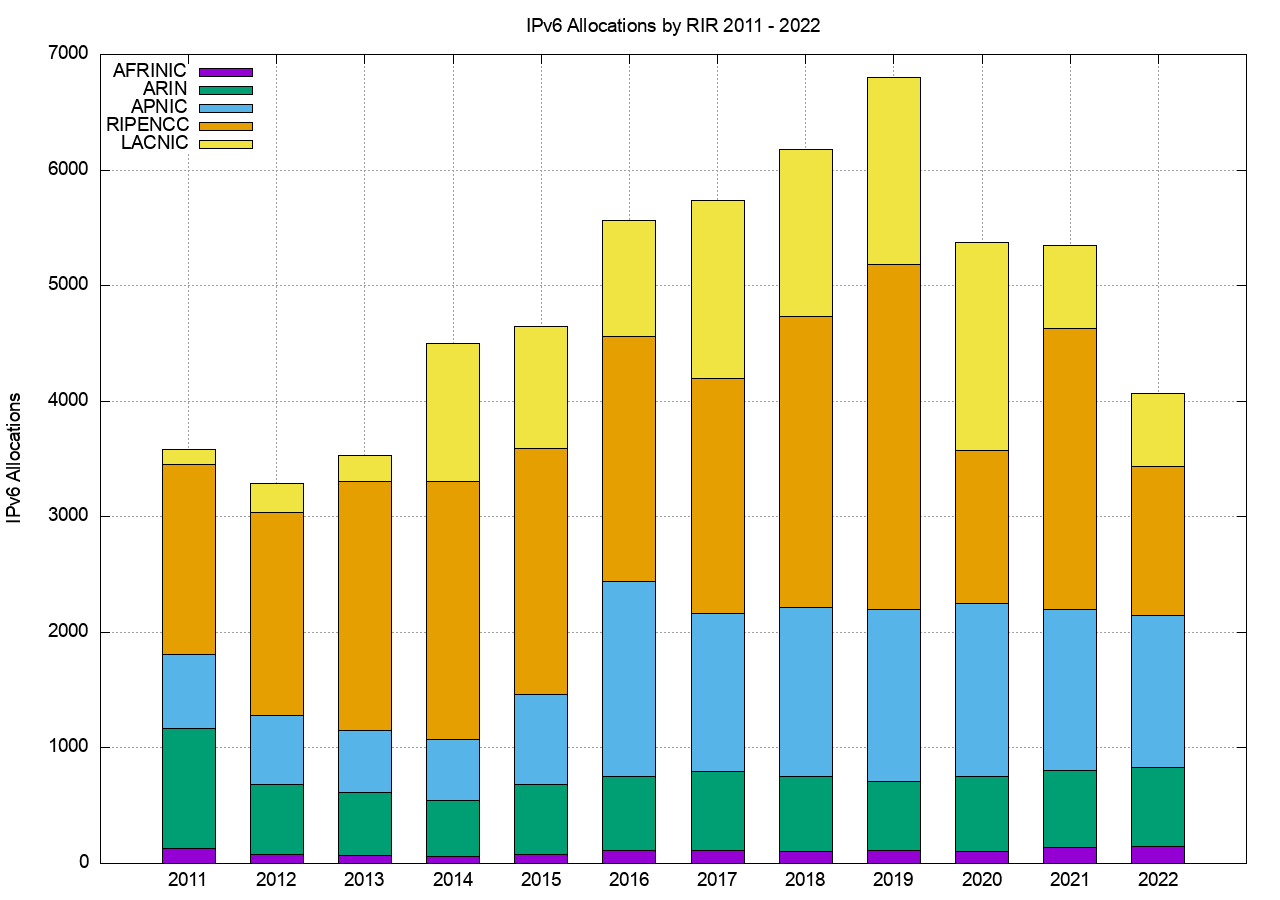
Figure 12 – Number of IPv6 Allocations per year
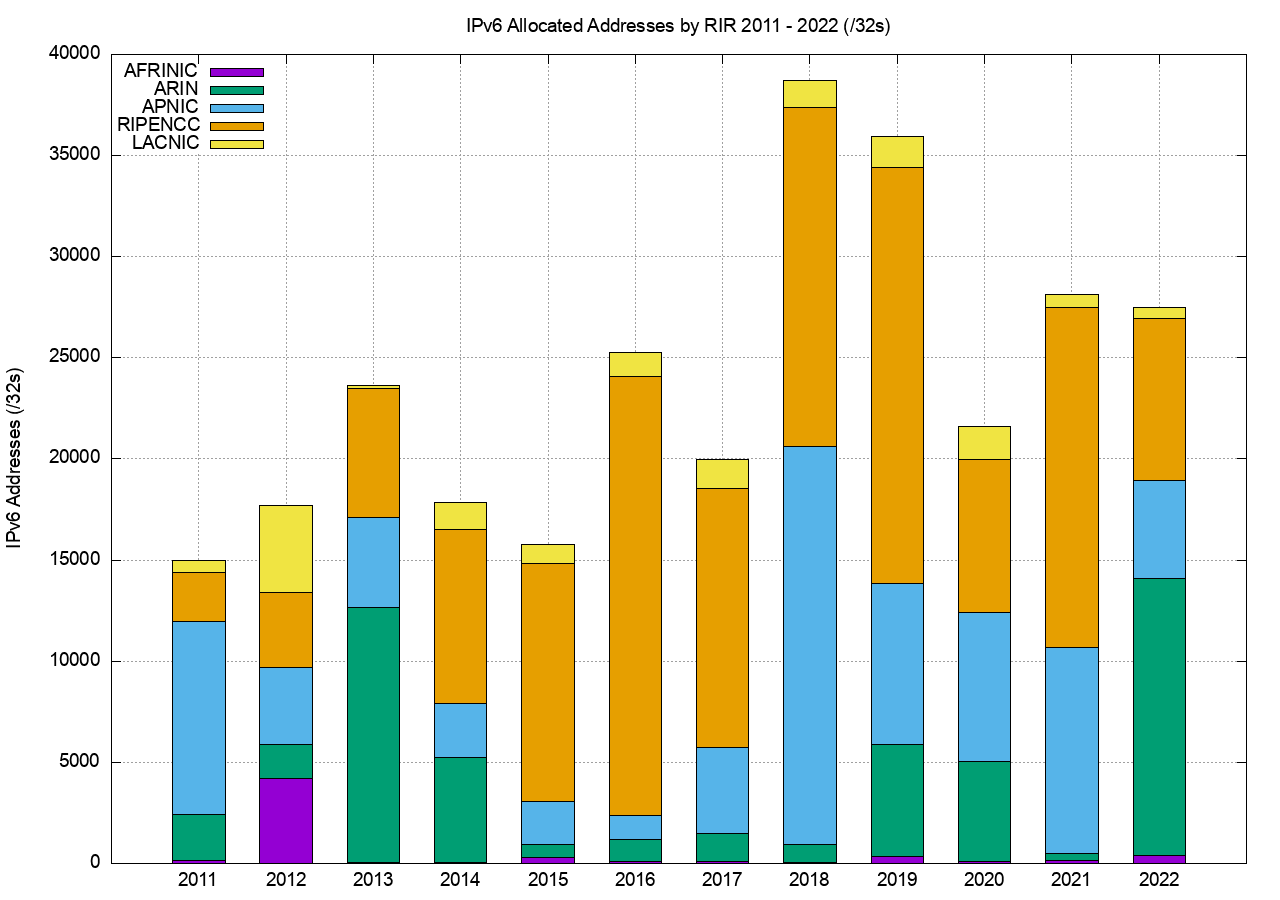
Figure 13 – Volume of IPv6 Allocations per year
It might be tempting to ascribe the decline in 2020 of IPv6 allocations from the RIPE NCC to the year where many European countries were hit hard by COVID-19 measures. Arguing against that is the observation that countries all over the world have been similarly affected, yet the decline in IPv6 allocation activity in 2020 is only seen in the data from the RIPE NCC. However, it’s an interesting question to ask as to why the IPv6 address allocation activity has slumped in the European economies, but not in China, the US and Brazil (Tables 18 and 19).
| Rank | 2018 | 2019 | 2020 | 2021 | 2022 | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | Brazil | 1,049 | Brazil | 1,112 | Brazil | 1,394 | USA | 619 | USA | 638 | ||||
| 2 | Russia | 638 | USA | 538 | USA | 588 | Russia | 576 | India | 377 | ||||
| 3 | USA | 595 | Russia | 502 | Indonesia | 389 | Brazil | 508 | Brazil | 339 | ||||
| 4 | Germany | 308 | Germany | 407 | India | 226 | Netherlands | 448 | Bangladesh | 239 | ||||
| 5 | China | 253 | Indonesia | 366 | Netherlands | 199 | India | 390 | Germany | 158 | ||||
| 6 | Indonesia | 213 | Netherlands | 342 | Germany | 192 | UK | 304 | Russia | 138 | ||||
| 7 | UK | 184 | UK | 223 | Bangladesh | 182 | Bangladesh | 213 | UK | 125 | ||||
| 8 | Bangladesh | 183 | Bangladesh | 202 | Russia | 128 | Germany | 196 | Indonesia | 113 | ||||
| 9 | India | 168 | France | 179 | Australia | 118 | Indonesia | 110 | Australia | 100 | ||||
| 10 | Netherlands | 162 | China | 165 | China | 115 | Hong Kong | 108 | Vietnam | 91 | ||||
Table 18 – IPv6 allocations by Year by Economy
Table 18 shows the countries who received the largest number of individual IPv6 allocations, while Table 19 shows the amount of IPv6 address space assigned on a per economy basis for the past 5 years (using units of /32s).
| Rank | 2018 | 2019 | 2020 | 2021 | 2022 | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | China | 17,647 | China | 6,787 | China | 6,765 | China | 5,424 | USA | 13,919 | ||||
| 2 | Russia | 4,675 | USA | 5,510 | USA | 5,051 | Russia | 4,409 | China | 4,354 | ||||
| 3 | Germany | 1,932 | Russia | 3,716 | Brazil | 1,358 | India | 4,281 | Russia | 925 | ||||
| 4 | UK | 1,209 | Germany | 2,522 | Netherlands | 1,331 | Netherlands | 3,390 | UK | 734 | ||||
| 5 | Singapore | 1,055 | Netherlands | 2,516 | Germany | 716 | UK | 2,249 | Germany | 706 | ||||
| 6 | Netherlands | 1,025 | UK | 1,355 | Russia | 715 | Germany | 896 | Moldova | 456 | ||||
| 7 | Brazil | 1,007 | France | 1,182 | UK | 552 | Ukraine | 651 | France | 404 | ||||
| 8 | USA | 874 | Italy | 1,052 | Italy | 391 | Lithuania | 633 | Netherlands | 397 | ||||
| 9 | Spain | 851 | Brazil | 1,049 | France | 390 | Brazil | 502 | Italy | 363 | ||||
| 10 | France | 722 | Spain | 854 | Turkey | 290 | USA | 491 | Brazil | 328 | ||||
Table 19 – IPv6 Address Allocation Volumes by Year by Economy (/32s)
We can also look at the allocated address pools for the 25 national economies with the largest allocated address pools in IPv6, and the current picture is shown in Table 20.
While the United States also tops this list in terms of the total pool of allocated IPv6 addresses, with some 19% of the total span of allocated IPv6 addresses, the per capita number is lower than many others in this list. Sweden has a surprisingly high number of allocated addresses per capita. The large IPv6 address pools allocated to some ISPs are likely due to early IPv6 allocations, made under a somewhat different allocation policy regime that that used today.
Some twenty years ago it was common practice to point out the inequities in the state of IPv4 address deployment. At the time, some US universities had more IPv4 addresses at their disposal than some highly populated developing economies, and the disparity was a part of the criticism of the address management practices that were used at the time. The RIR system was intended to address this issue of predisposition to a biased outcome. The concept behind the system that within the regional community each community had the ability to develop their own address distribution policies and could determine for themselves what they meant by such terms as “fairness” and “equity” and then direct their regional address registry to implement these policies. While IPv4 had a very evident early adopter reward, in that the address allocations in the IPv4 class-based address plan could be quite extravagant, the idea was that in IPv6, where the address allocations were developed from the outset through local bottom-up policy determinate frameworks, such evident inequities in the outcome would be avoided, or so it was hoped. It was also envisaged that with such a vast address plan provided by 128 bits of address space, the entire concept of scarcity and inequity would be largely irrelevant. 2128 is a vast number and the entire concept of comparison between two vast pools of addresses is somewhat irrelevant. So, when we look at the metric of /48s per head of population, don’t forget that a /48 is actually 80 bits of address space, which is massively larger than the entire IPv4 address space. Even India’s average of 0.1 /48s per capita is still a truly massive number of IPv6 addresses!
However, before we go too far down this path it is also useful to bear in mind that the 128 bits of address space in IPv6 has become largely a myth. We sliced off 64 bits in the address plan for no particularly good reason, as it turns out. We then sliced off a further 16 bits for again no particularly good reason. 16 bits for end site addresses allows for some 65,000 distinct networks within each site, which is somewhat outlandish in pretty much every case. The result is that the vastness of the address space represented by 128 bits in IPv6 is in fact not so vast in practice. The usable address prefix space in IPv4 roughly equates a /32 end address in IPv4 with around a /48 prefix in IPv6. So perhaps this comparison of /48s per capita is not entirely fanciful, and there is some substance to the observation that there are inequities in the address distribution in IPv6 so far. However, unlike IPv4, the exhaustion of the IPv6 address space is still quite some time off, and we still believe that there are sufficient IPv6 addresses to support a uniform address utilisation model across the entire world of silicon over time.
There is a larger question about the underlying networking paradigm in today’s public network. IPv6 attempts to restore the 1980’s networking paradigm of a true peer-to-peer network where every connected device is capable of sending packets to any other connected device. However, today’s networked environment regards such unconstrained connectivity as a liability. Exposing an end client device is regarded as being unnecessarily foolhardy, and today’s network paradigm relies on client-initiated transactions. This is well-suited to NAT-based IPv4 connectivity, and the question regarding the long term future of an IPv6 Internet is whether we want to bear the costs of maintaining end-client unique addressing plans, or whether NATs in IPv6 might prove to be a most cost-effective service platform for the client side of client/server networks.
| Rank | CC | Allocated (/48s) | % Total | /48s p.c. | Advertised /48s | % Deployment | Name |
|---|---|---|---|---|---|---|---|
| 1 | US | 4,711,773,641 | 19.3% | 13.9 | 1,360,009,679 | 13.2% | USA |
| 2 | CN | 4,218,814,563 | 17.3% | 3.0 | 1,697,013,310 | 16.5% | China |
| 3 | DE | 1,535,836,883 | 6.3% | 18.4 | 1,053,057,966 | 10.2% | Germany |
| 4 | GB | 1,498,022,128 | 6.1% | 22.1 | 472,013,191 | 4.6% | UK |
| 5 | RU | 1,115,226,419 | 4.6% | 7.7 | 223,745,017 | 2.2% | Russia |
| 6 | FR | 971,780,506 | 4.0% | 15.0 | 174,722,243 | 1.7% | France |
| 7 | NL | 829,817,132 | 3.4% | 47.2 | 359,311,107 | 3.5% | Netherlands |
| 8 | IT | 669,650,985 | 2.7% | 11.4 | 418,702,711 | 4.1% | Italy |
| 9 | JP | 664,477,902 | 2.7% | 5.4 | 508,779,422 | 4.9% | Japan |
| 10 | AU | 621,544,682 | 2.5% | 23.6 | 311,060,736 | 3.0% | Australia |
| 11 | BR | 544,695,204 | 2.2% | 2.5 | 392,640,662 | 3.8% | Brazil |
| 12 | SE | 453,247,324 | 1.9% | 42.8 | 356,204,225 | 3.5% | Sweden |
| 13 | IN | 430,900,264 | 1.8% | 0.3 | 360,281,569 | 3.5% | India |
| 14 | ES | 399,048,743 | 1.6% | 8.4 | 98,712,690 | 1.0% | Spain |
| 15 | PL | 396,230,899 | 1.6% | 9.8 | 222,331,434 | 2.2% | Poland |
| 16 | AR | 351,799,399 | 1.4% | 7.7 | 284,283,185 | 2.8% | Argentina |
| 17 | KR | 345,636,875 | 1.4% | 6.7 | 4,518,648 | 0.0% | Korea |
| 18 | ZA | 320,345,258 | 1.3% | 5.3 | 290,878,909 | 2.8% | South Africa |
| 19 | EG | 270,204,932 | 1.1% | 2.4 | 270,008,321 | 2.6% | Egypt |
| 20 | CH | 248,775,100 | 1.0% | 28.4 | 115,094,843 | 1.1% | Switzerland |
| 21 | TR | 234,422,302 | 1.0% | 2.7 | 45,390,112 | 0.4% | Turkey |
| 22 | CZ | 194,642,039 | 0.8% | 18.5 | 112,187,291 | 1.1% | Czech Republic |
| 23 | IR | 188,088,327 | 0.8% | 2.1 | 32,936,166 | 0.3% | Iran |
| 24 | UA | 182,845,623 | 0.7% | 4.8 | 70,103,860 | 0.7% | Ukraine |
| 25 | TW | 169,148,435 | 0.7% | 7.1 | 155,106,153 | 1.5% | Taiwan |
Table 20 – IPv6 Allocated Address pools per National Economy
To what extent are allocated IPv6 addresses visible as advertised prefixes in the Internet’s routing table?
Figure 14 shows the overall counts of advertised, unadvertised and total allocated address volume for IPv6 since 2010, while Figure 15 shows the advertised address span as a percentage of the total span of allocated and assigned IPv6 addresses.
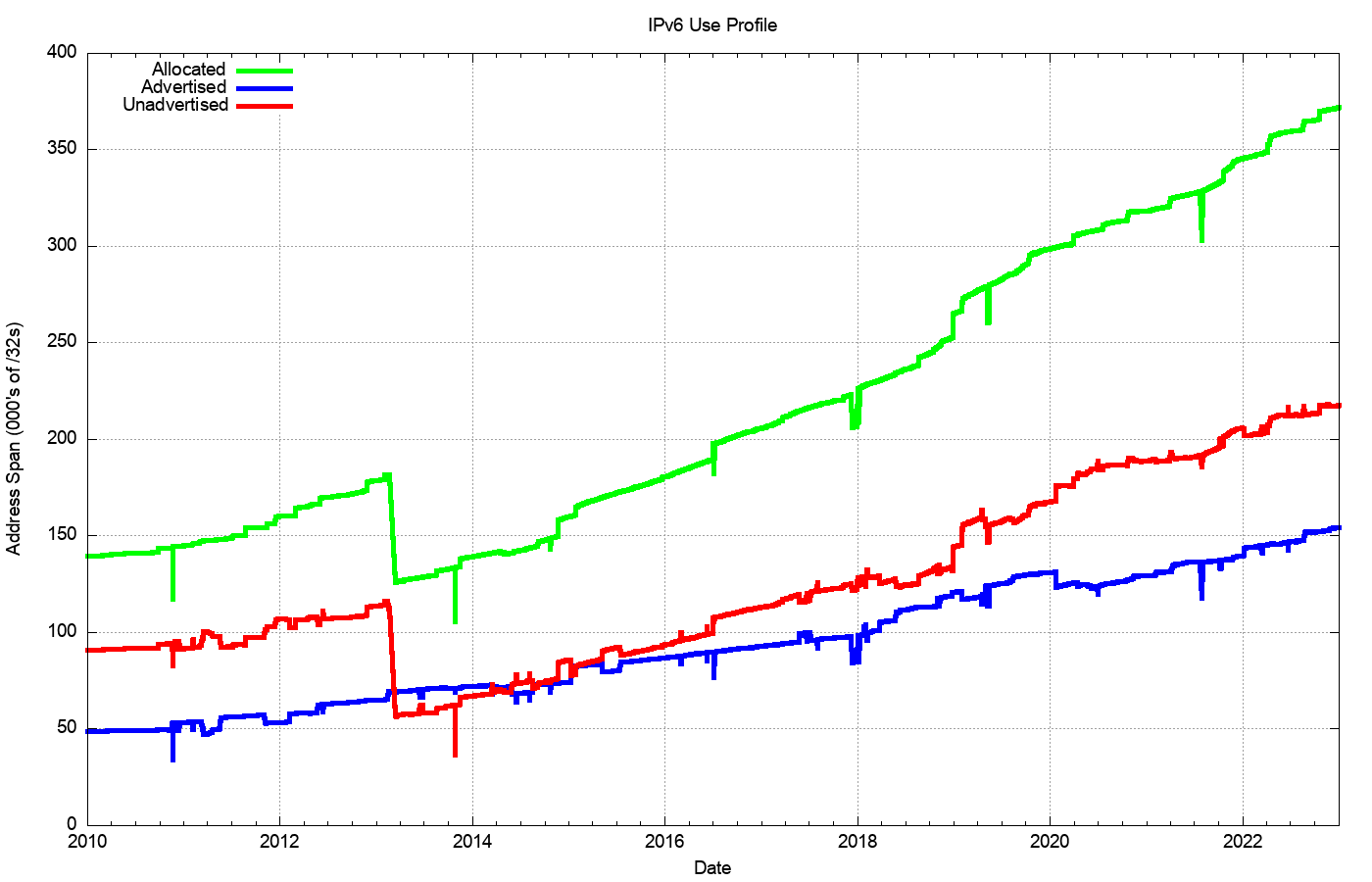
Figure 14 – Allocated, Unadvertised and Advertised IPv6 addresses
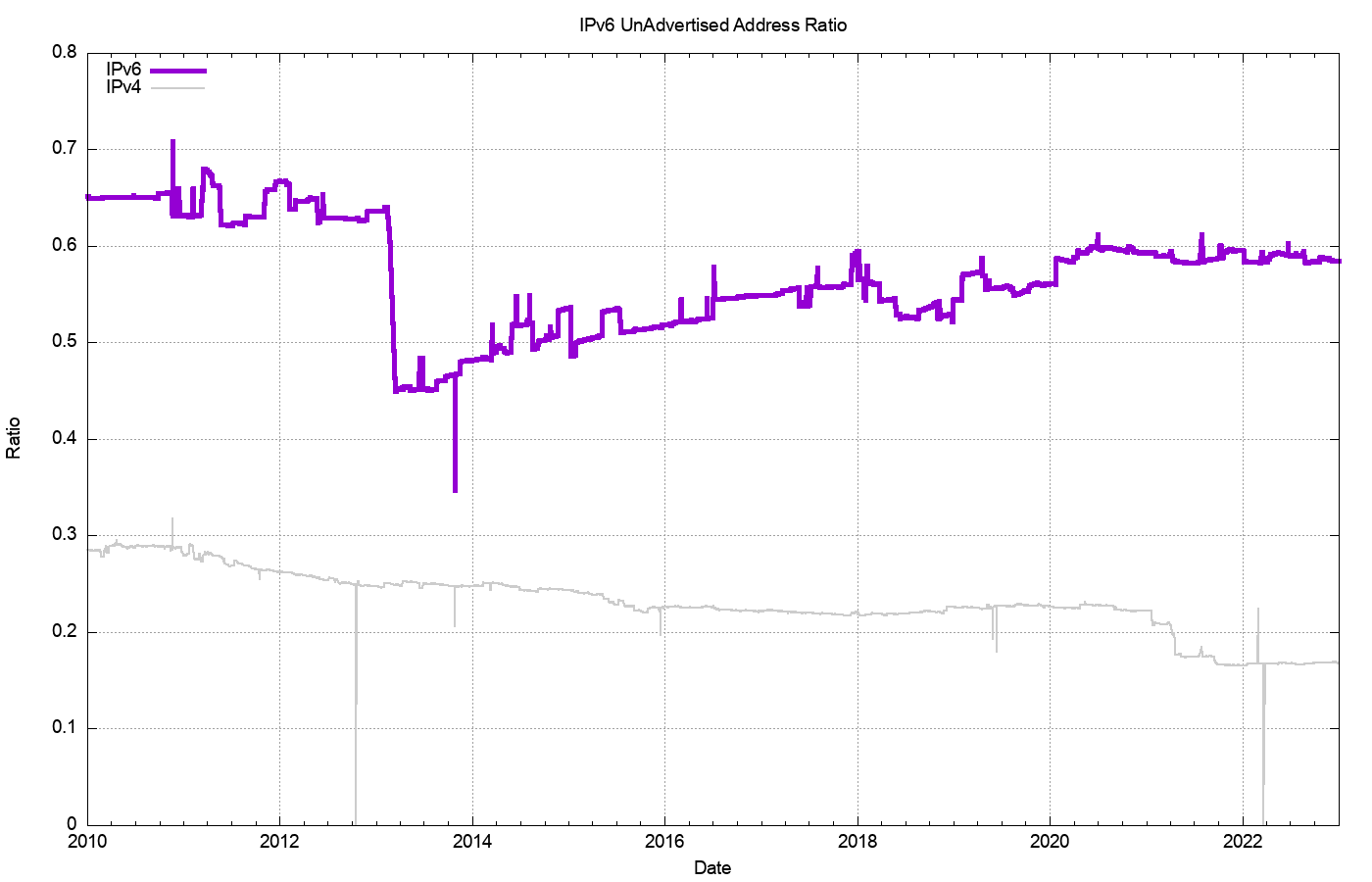
Figure 15 – Advertised IPv6 Addresses as a percentage of the Allocated Address Pool
The drop in the allocated address span in 2013 is the result of a change in LACNIC where a single large allocation into Brazil was replaced by the recording of direct allocation and assignments to ISPs and similar end entities.
From a history of careful conservation of IPv4 addresses, where some 77% of allocated or assigned IPv4 addresses are advertised in the BGP routing table, a comparable IPv6 figure of 40% does not look all that impressive. But that’s not the point. We chose the 128-bit address size in IPv6 to allow addresses to be used without overriding concerns about conservation. We are allowed to be inefficient in address utilisation.
At the start of 2023 we have advertised an IPv6 address span which is the equivalent of some 157,000 /32s, or some 10.3 billion end-site /48 prefixes. That is just 0.004% of the total number of /48 prefixes in IPv6.
The Outlook for the Internet
Once more the set of uncertainties that surround the immediate future of the Internet are considerably greater than the set of predictions that we can be reasonably certain about.
The year 2017 saw a sharp rise in IPv6 deployment, influenced to a major extent by the deployment of IPv6 services in India, notably by the Reliance Jio service. The next year, 2018, was a quieter year, although the rise in the second half of the year is due to the initial efforts of mass scale IPv6 deployment in the major Chinese service providers. This movement accelerated in 2019 and the overall move of some 5% in IPv6 deployment levels had a lot to do with the very rapid rise of the deployment of IPv6 in China. There has been an ongoing rise in the level of IPv6 within China, and the measured level of IPv6 has risen from 23% of the user base to 28% over 2022, or an expansion of the Chinese IPv6 user pool by 41M end clients.
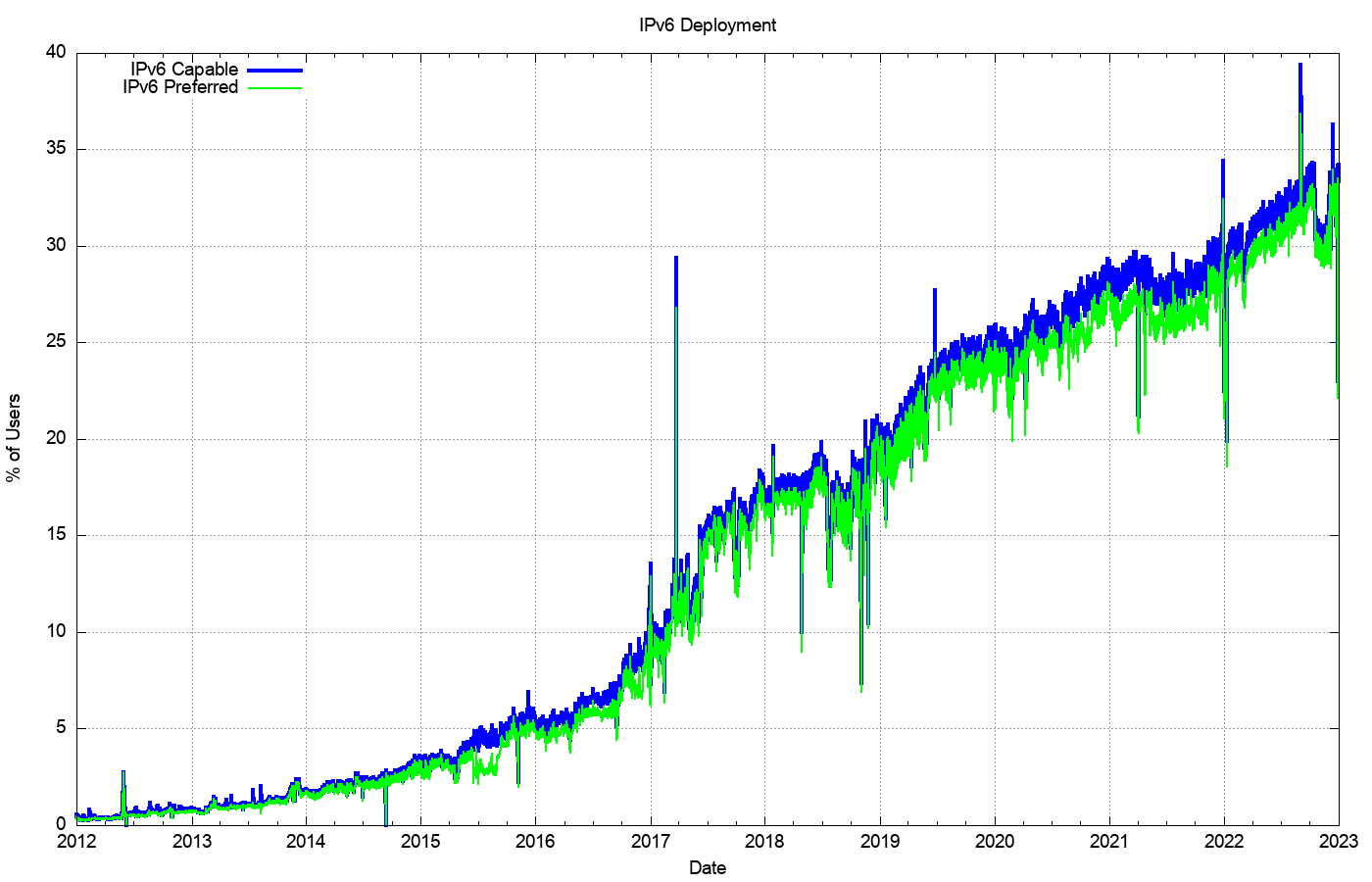
Figure 16 – IPv6 Deployment measurement 2010 – 2021
In 2022 the growth patterns for IPv6 are more diffuse around the world with a 2.5% overall growth rate, although there has been steady growth in IPv6 deployment in France (19% growth), Nepal (15% growth), Israel (14%) and the UK (10%). The regions where IPv6 deployment is low compared to this 33% Internet-wide average includes Africa, Southern and Eastern Europe, the Middle East and Central Asia (Figure 17).
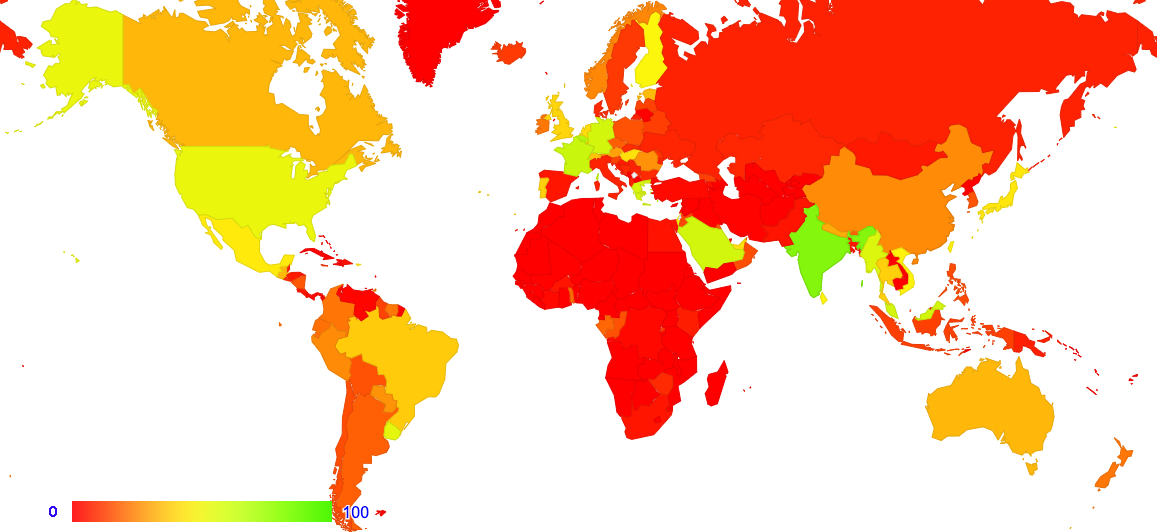
Figure 17 – IPv6 Deployment measurement – December 2022
While a number of service operators have reached the decision point that the anticipated future costs of NAT deployment are unsustainable for their service platform, there remains a considerable school of thought that says that NATs will cost effectively absorb some further years of Internet population growth. At least that’s the only rationale I can ascribe to a very large number of service providers who are making no visible moves to deploy Dual-Stack services at this point in time. Given that the ultimate objective of this transition is not to turn on Dual-Stack everywhere, but to turn off IPv4, there is still some time to go, and the uncertainty lies in trying to quantify what that time might be.
The period of the past decade has been dominated by the mass marketing of mobile internet services, and the Internet’s growth rates for 2014 through to 2016 perhaps might have been the highest so far recorded. This would’ve been visible in the IP address deployment data were it not for the exhaustion of the IPv4 address pool. In address terms this growth in the IPv4 Internet is being almost completely masked by the use of Carrier Grade NATs in the mobile service provider environment, so that the resultant demands for public addresses in IPv4 are quite low and the real underlying growth rates in the network are occluded by these NATs. In IPv6 the extremely large size of the address space masks out much of this volume. A single IPv6 /20 allocation to an ISP allows for 268 million /48 allocations, or 68 billion /56 allocations, so much of the growth in IPv6-using networks is simply hidden behind the massive address plan that lies behind IPv6.
It has also been assumed that we should see IPv6 address demands for deployments of large-scale sensor networks and other forms of deployments that are encompassed under the broad umbrella of the Internet of Things. This does not necessarily imply that the deployment is merely a product of an over-hyped industry, although that is always a possibility. It is more likely to assume that, so far, such deployments are taking place using private IPv4 addresses, and they rely on NATs and application-level gateways to interface to the public network. Time and time again we are lectured that NATs are not a good security device, but in practice NATs offer a reasonable front-line defence against network scanning malware, so there may be a larger story behind the use of NATs and device-based networks than just a simple conservative preference to continue to use an IPv4 protocol stack.
More generally, we are witnessing an industry that is no longer using technical innovation, openness and diversification as its primary means of propulsion. The widespread use of NATs in IPv4 limit the technical substrate of the Internet to a very restricted model of simple client/server interactions using TCP and UDP. The use of NATs force the interactions into client-initiated transactions, and the model of an open network with considerable flexibility in the way in which communications take place is no longer being sustained in today’s network. Incumbents are entrenching their position and innovation and entrepreneurialism are taking a back seat while we sit out this protracted IPv4/IPv6 transition.
What is happening is that today’s internet carriage service is provided by a smaller number of very large players, each of whom appear to be assuming a very strong position within their respective markets. The drivers for such larger players tend towards risk aversion, conservatism and increased levels of control across their scope of operation. The same trends of market aggregation are now appearing in content provision, where a small number of content providers are exerting a completely dominant position across the entire Internet.
The evolving makeup of the Internet industry has quite profound implications in terms of network neutrality, the separation of functions of carriage and service provision, investment profiles and expectations of risk and returns on infrastructure investments, and on the openness of the Internet itself. Given the economies of volume in this industry, it was always going to be challenging to sustain an efficient, fully open and competitive industry, but the degree of challenge in this agenda is multiplied many-fold when the underlying platform has run out of the basic currency of IP addresses. The pressures on the larger players within these markets to leverage their incumbency into overarching control gains traction when the stream of new entrants with competitive offerings dries up, and the solutions in such scenarios typically involve some form of public sector intervention directed to restore effective competition and revive the impetus for more efficient and effective offerings in the market.
As the Internet continues to evolve, it is no longer the technically innovative challenger pitted against venerable incumbents in the forms of the traditional industries of telephony, print newspapers, television entertainment and social interaction. The Internet is now the established norm. The days when the Internet was touted as a poster child of disruption in a deregulated space are long since over, and these days we appear to be increasingly looking further afield for a regulatory and governance framework that can challenge the increasing complacency of the newly-established incumbents.
It is unclear how successful we will be in this search. We can but wait and see.